Field of Invention
The present disclosure relates to artificial intelligence systems for healthcare data processing, and more particularly to a neuro-symbolic AI system that performs automated medical coding and risk adjustment through member-wise chart review using autonomous AI modules that combine neural networks with structured reasoning for hierarchical condition category (HCC) code identification and validation.
Background
Healthcare organizations increasingly rely on accurate medical coding and risk adjustment processes to ensure proper reimbursement and compliance with regulatory requirements. Risk adjustment systems, particularly those utilizing Hierarchical Condition Categories (HCC), serve as mechanisms to predict future healthcare costs by translating patient medical histories into standardized codes that reflect disease burden and expected resource utilization.
Traditional medical coding workflows involve manual review of patient electronic medical records by trained human coders who examine clinical documentation to identify appropriate diagnosis codes. These manual processes are time-consuming, labor-intensive, and subject to human error and inconsistency. The conventional approach typically follows a Date of Service (DOS)-wise methodology, where coders review individual patient encounters in isolation, often missing the broader longitudinal context of a patient’s health status across multiple visits and time periods.
Conventional solutions have attempted to address these challenges through various automated coding systems and natural language processing tools. However, these approaches often suffer from limitations including inadequate contextual understanding, fragmented analysis that fails to capture comprehensive patient health profiles, and insufficient integration of structured reasoning with pattern recognition capabilities. Many existing systems rely on simple keyword matching or basic machine learning models that lack the sophistication to handle complex medical terminology and clinical reasoning patterns.
US Patent Application Publication No. US-20190189253-A1 discloses a medical condition verification system that receives patient electronic medical record data and performs cognitive analysis to identify evidential data supportive of medical conditions. The system generates risk measures based on machine learned relationships of medical factors and provides outputs representing the risk of patients having associated medical conditions. However, this approach focuses primarily on verification of existing medical codes rather than comprehensive automated coding, and lacks the integrated neurosymbolic architecture that combines neural networks with structured reasoning for enhanced accuracy and explainability.
US Patent Application Publication No. US-20200381090-A1 describes methods for generating patient context vectors as low-dimensional representations of patient medical context using deep learning networks and multi-task learning. The system combines ICD codes and clinical text to create patient context vectors for disease prediction and risk assessment. Nevertheless, this approach is limited to vector-based representations and does not provide the comprehensive member-wise audit capabilities or the structured reasoning components that enable systematic validation and evidence extraction for regulatory compliance.
Keeping in view the challenges associated with the state of art, there is a need for a neurosymbolic artificial intelligence system that performs automated medical coding through member-wise chart review, combining neural network pattern recognition with structured reasoning capabilities to analyze complete patient records longitudinally. Such a solution would provide enhanced accuracy in HCC code identification, automated evidence validation, and comprehensive risk adjustment processing while reducing manual workload and improving coding consistency across healthcare organizations.
Objectives
The primary objective of the present invention is to provide a neurosymbolic AI system that automates medical coding and risk adjustment through comprehensive member-wise chart review, combining neural network pattern recognition with structured reasoning to improve accuracy and reduce manual workload in healthcare coding processes.
Another objective of the present invention is to shift from conventional date-of service-wise review methodologies to a longitudinal analysis approach that may capture complete patient health status across multiple encounters, enabling detection of chronic conditions that may be missed in fragmented encounter-based coding methods.
Another objective of the present invention is to provide a multi-agent pipeline architecture comprising specialized autonomous modules that may perform distinct functions including encounter segmentation, compliance validation, clinical data extraction, neurosymbolic coding, MEAT evidence validation, hallucination prevention, and member-wise synthesis for comprehensive medical coding automation.
Another objective of the present invention is to implement automated evidence validation according to Monitoring, Evaluation, Assessment, and Treatment (MEAT) criteria that ensure all recommended codes meet regulatory requirements with supporting clinical documentation for compliance purposes.
Another objective of the present invention is to provide confidence scoring algorithms that may incorporate multiple weighted parameters including frequency of documentation, evidence context, MEAT evidence strength, code specificity, and condition type to enable automated triage decisions and hierarchical suppression logic.
Another objective of the present invention is to reduce cognitive fatigue among human coders by filtering routine coding decisions through automated processing that may allow coding professionals to focus attention on complex cases requiring specialized judgment rather than processing high volumes of straightforward coding decisions.
Yet another objective of the present invention is to facilitate detection of under-coded chronic conditions documented across multiple visits through comprehensive longitudinal analysis that may improve risk adjustment accuracy and ensure proper reimbursement for healthcare organizations.
Summary
The present invention relates to a neurosymbolic AI system for automated medical coding and risk adjustment that comprises a multi-agent pipeline architecture configured to process patient medical records, an encounter segmentation agent that parses longitudinal patient charts and identifies discrete clinical encounters by date of service, a compliance check agent that validates encounters against CMS guidelines for HCC coding eligibility, a clinical data extraction agent that extracts medically relevant information based on configurable rules, a neurosymbolic coding agent that combines neural network pattern recognition with structured reasoning from large knowledge models to assign ICD-10 codes, a MEAT validation agent that identifies supporting evidence according to Monitoring, Evaluation, Assessment, and Treatment criteria, a hallucination validator agent that cross-references recommendations against a medical knowledge graph, and a member-wise synthesis module that aggregates findings across all patient encounters to generate HCC code recommendations with confidence scores.
The system operates by ingesting longitudinal patient charts and claims data, segmenting annual patient records into individual clinical encounters, processing each encounter through the multi-agent analysis engine to extract clinical information and assign appropriate ICD-10 codes with supporting evidence, performing member-wise synthesis to consolidate findings across all patient visits within a given period, calculating confidence scores based on multiple weighted parameters including frequency of documentation, evidence context, MEAT evidence strength, code specificity, and condition type, and applying decision logic to categorize codes into autoaccept buckets or human validation queues based on confidence thresholds and hierarchical suppression rules.
The invention provides enhanced accuracy in medical coding through comprehensive longitudinal analysis rather than fragmented encounter-based reviews, reduces manual workload by automating a substantial portion of coding decisions while maintaining high precision, improves coding consistency by applying systematic rules and reasoning across complete patient records, enables detection of under-coded chronic conditions that may be missed in traditional date-of-service reviews, facilitates compliance through automated evidence validation and structured documentation, and reduces cognitive fatigue among human coders by filtering routine decisions and allowing focus on complex cases requiring expert judgment.
Brief Description
Non-limiting and non-exhaustive examples are described with reference to the following figures.
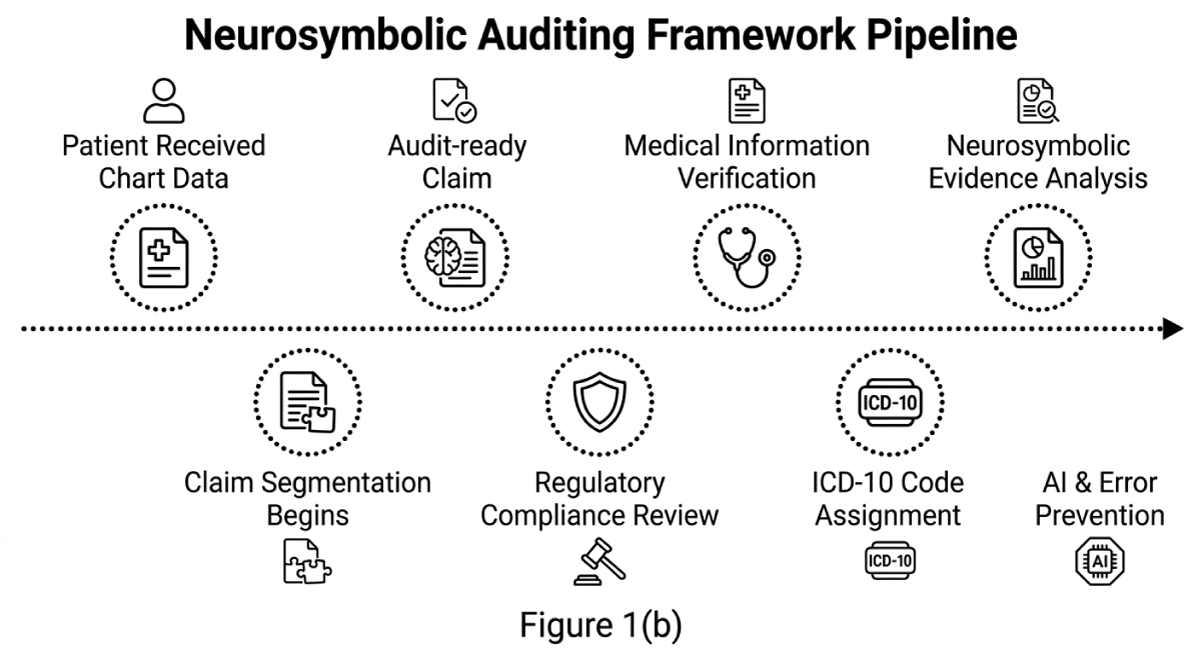
Figure 1(a-b) illustrates a workflow diagram of a neurosymbolic auditing framework pipeline for medical coding.
FIG. 2 illustrates a block diagram of an automated risk adjustment coding system.
Detailed Description
The following detailed description and embodiments set forth herein below are merely exemplary out of the wide variety and arrangement of instructions which can be employed with the present invention. The present invention may be embodied in other specific forms without departing from the spirit or essential characteristics thereof. All the features disclosed in this specification may be replaced by similar other or alternative features performing similar or same or equivalent purposes. Thus, unless expressly stated otherwise, they all are within the scope of the present invention.
Accordingly, those of ordinary skill in the art will recognize that various changes and modifications of the embodiments described herein can be made without departing from the scope of the invention. In addition, descriptions of well-known functions and constructions are omitted for clarity and conciseness.
The terms and words used in the following description and claims are not limited to the bibliographical meanings but are merely used to enable a clear and consistent understanding of the invention. Accordingly, it should be apparent to those skilled in the art that the following description of exemplary embodiments of the present invention are provided for illustration purpose only and not for the purpose of limiting the invention.
It is to be understood that the singular forms “a,” “an,” and “the” include plural referents unless the context clearly dictates otherwise.
It should be emphasized that the term “comprises/comprising” when used in this specification is taken to specify the presence of stated features, integers, steps, or components but does not preclude the presence or addition of one or more other features, integers, steps, components, or groups thereof.
The present invention relates to a method of visual paraphrase attack safe and distortion free image watermarking technique for AI-generated images. The method strategically embeds watermarks within stable regions known as a non-melting point (NMPs). The method also incorporates noisy burnishing to counter reverse engineering efforts aimed at locating the NMPs to disrupt the embedded watermark, thereby enhancing durability.
This method introduces PECCAVI, the first visual paraphrase attack safe and distortion free image watermarking technique. In visual paraphrase attacks, an image is altered while preserving its core semantic regions, termed Non-Melting Points (NMPs). The PECCAVI strategically embeds watermarks within the NMPs and employs multi-channel frequency domain watermarking. The method also incorporates noisy burnishing to counter reverse engineering efforts aimed at locating the NMPs to disrupt the embedded watermark, thereby enhancing durability. The concept of visual paraphrasing attack refers to generating variations of an image that retain the same semantic content while altering the visual presentation. Further, the method includes an image-to-image paraphrased approach that ensures reliable adherence to the original image’s appearance and meaning, even within this variable parameter space, delivering a consistent and structurally faithful visual paraphrase.
This method introduces PECCAVI is the first visual paraphrase attack-safe, distortion-free image watermarking technique. With the rise of AI-generated misinformation, the PECCAVI may contribute significantly to the greater social good. The method surpasses existing watermarking existing techniques which it requires substantial computational resources.
The method (PECCAVI), for visual paraphrase attack safe and distortion-free image watermarking for AI-generated images, is focused on the placement of the watermark, method of watermarking, the need for a more sophisticated detection mechanism, assessment method resistance to visual paraphrase attacks, and whether the watermarking process distorts the 1original concept excessively.
Figure 1(a) in combination with figure 1(b) illustrates the method of visual paraphrase attack safe and distortion-free image watermarking technique for AI-generated images. Figure 1(b) illustrates steps of the method for image watermarking encompasses NMP detection, multi channel watermark embedding, noisy burnishing, and encrypted metadata addition. These components collectively ensure robust, low-distortion watermarks that resist paraphrase attacks, safeguarding AI-generated images from unauthorized alterations.
Further, the method comprises steps of identification of one or more stable regions that are unaffected by paraphrasing, at step 102. Further, at least five paraphrases are generated, at step 104. Further, the non-melting points are located, across variations, by applying intersection over union (IoU), at step 106. Further, the potential non-melting point (NMP) is identified by using non-maximum suppression (NMS). Further, the non-maximum suppression (NMS) merges highly overlapping boxes, ensuring that only the most representative areas are retained, resulting in a clean set of stable regions across the images, at step 108. Further, the non-melting points (NMPs) are embedded with one or more watermark signals, at step 110. Further, the NMP-embedded watermarks are subjected to resilience assessment against paraphrasing, at Step 112. Further, the NMP-embedded watermarks are prevented from paraphrasing by using one or more techniques, Step 114. Further, the watermarked image quality is improved by blending it with the original image for balancing quality and watermark strength by applying adaptive image enhancement, at step 116.
Further, the method of identifying the non-melting points in the image comprises the detection of salient regions in the image based on a number of features of the images. Further, the features may include but not limited to color contrast, texture, or edges. Further, the potential nonmelting point is identified by using non-maximum suppression (NMS). Further, the non-maximum suppression (NMS) merges highly overlapping boxes, ensuring that only the most representative areas are retained, resulting in a clean set of stable regions across the images. Further, a stability score is assigned, based on the frequency of the boxes across one or more images, to each of the boxes, with lower scores indicating higher occurrences across multiple paraphrased images.
In the preferred embodiment, at first, the method for visual paraphrasing attacks safe and distortion-free image watermarking for AI-generated images comprises steps of, an identification of one or more stable regions unaffected by paraphrasing. The stable regions are ideal for embedding watermark signals, as the stable regions are less likely to be altered. Also, the stable regions are referred as non-melting points or non-melting regions.
Further, the non-melting points (NMPs) detection involves two main steps including salient region detection and non-melting points (NMPs) location. Further, the salient region detection in image processing identifies the most “salient” or visually prominent areas within the image, based on unique features like color contrast, texture, or edges. Further, the saliency detection is performed using XRAI method, as shown in Figure 2.
In an another embodiment, the salient region detection is performed through a number of methods including Vanilla Gradient, Smooth Grad, Vanilla Integrated (Vanilla I Grad), Smooth Grad Integrated (Smooth I Grad), XRAI, Grad CAM, Smooth Grad Grad CAM, and MSI-Net, as shown in figure 2(a).
Figure 2(b) NMPs across various paraphrased versions are displayed. Each row corresponds to a different paraphrase, with four columns: the original image, saliency map, top salient regions highlighted in red, least in blue, and refined bounding boxes obtained after applying NMS and IoU. Further, the non-melting points (NMPs) are located by identifying the most stable areas in the image.
Further, at-least five automatic paraphrases are generated. After identifying key regions in each paraphrased image, applying Intersection over Union (IoU) to locate the most stable areas across variations, referred to as the non-melting points (NMPs). The intersection over union (IoU) quantifies the overlap between boxes across images, highlighting regions that consistently appear in similar locations. Once potential NMPs are identified which is selected using non-maximum suppression (NMS). The non-maximum suppression (NMS) merges highly overlapping boxes, ensuring that only the most representative areas are retained, resulting in a clean set of stable regions across images. Each box is then assigned a stability score, based on the frequency of the box, across images, with lower scores indicating higher occurrences across the paraphrased images. This score reflects each region’s robustness as the non-melting points (NMPs). If no stable regions are found, a default box is added to ensure robustness.
Figure 3 illustrates progression of multichannel watermarking at different diffusion steps. Each step shows how the watermark integrates into the image through the multi-channel frequency domain. Further, the one or more watermark signals are embedded with the identified non-melting points (NMPs) using a multi-channel strength watermarking approach to enhance robustness against de-watermarking attacks. Further, the watermark strength is determined before embedding the watermark with the non-melting points (NMPs). As stronger paraphrasing removes watermarks more effectively. Therefore, using a higher watermark strength in such non-melting points (NMPs) to make the method more resilient. Watermark strength is determined by the distance between rings within the watermark, with smaller distances indicating greater strength. For example, Channel 4 shows a smaller ring distance (0.5), while Channel 3 reflects a larger distance (0.75), as shown in figure 3. Strength values range from 0 to 1.0, depending on the number of paraphrases containing the NMP: Ws = max (0.1, 1 − 0.25 · (n − 1)), n ∈ {1, 2, 3, 4, 5}. Here n represents the number of regions that an NMP appears in out of the at least five paraphrases. Further, the watermark is embedded across multiple channels, which provides higher detection scores due to overlapping bounding box watermarks.
Further, the NMP-embedded watermarks are assessed against paraphrasing. Further, the NMP-based watermarking faces two key challenges including assessing the resilience of NMPembedded watermarks against further paraphrasing and anticipating potential countermeasures from attackers who may reverse engineer methods to detect and distort NMPs, reducing watermark detectability. Two strategies are implemented to ensure robustness of the NMP-embedded watermarks including random patching to embed additional watermarks, and noisy burnishing to prevent NMP detection.
Further, the random patching is implemented to enhance the security of the non-melting points (NMPs). Once all NMPs are detected and saved, the smallest NMPs are identified. Further, an additional NMP is generated, of the same shape as the smallest NMP, at a random, nonoverlapping location. The selection may be randomized using a vendor-specific pseudo-random algorithm. Watermarks are then embedded in these randomly placed NMPs, similar to the original NMPs, using either single-channel or multi-channel approaches.
Figure 4 illustrates noisy burnishing disrupts saliency detection in watermarked images hindering attackers from locating (NMPs) or altering watermarked areas. This technique preserves the frequency-based watermark, ensuring high detectability while enhancing security against tampering. Attackers may attempt to identify salient regions of the image to remove the watermark. This may be countered by adding adversarial noise to the watermarked image, which disrupts the detection of these salient regions. Noisy burnishing disrupts saliency detection in watermarked images hindering attackers from locating NMPs or altering watermarked areas. The method preserves the frequency-based watermark, ensuring high detectability while enhancing security against tampering.
Figure 5 illustrates a pictorial representation of embedding encrypted metadata with NMP locations in images, ensuring secure watermark verification while meeting regulatory standards and resisting reverse engineering by hiding precise watermark coordinates. A significant challenge is enabling vendors or text to image system providers to verify that the image is PECCAVIwatermarked without knowing the exact locations of random patches or NMPs. Further, the method embeds encrypted metadata containing this information—random patch locations and NMP bounding boxes. Using a secure key, vendors may decrypt the metadata to verify the watermark, ensuring both security and practicality.
Further, the method aligns with California’s mandate for accessible AI detection tools and robust watermarking for AI-generated content, as shown in figure 5. While noisy burnishing locations are stored, one might question storing random patch data. If vendors know the pseudorandom patch algorithm, they could compute these locations, but storing the computed locations reduces computational overhead and allows flexibility in case the algorithm changes.
The following detailed description and embodiments set forth herein below are merely exemplary out of the wide variety and arrangement of instructions which can be employed with the present invention. The present invention may be embodied in other specific forms without departing from the spirit or essential characteristics thereof. All the features disclosed in this specification may be replaced by similar other or alternative features performing similar or same or equivalent purposes. Thus, unless expressly stated otherwise, they all are within the scope of the present invention.
Accordingly, those of ordinary skill in the art will recognize that various changes and modifications of the embodiments described herein can be made without departing from the scope of the invention. In addition, descriptions of well-known functions and constructions are omitted for clarity and conciseness.
The terms and words used in the following description and claims are not limited the bibliographical meanings but are merely used to enable a clear and consistent understanding of the invention. Accordingly, it should be apparent to those skilled in the art that the following description of exemplary embodiments of the present invention are provided for illustration purpose only and not for the purpose of limiting the invention.
It is to be understood that the singular forms “a,” “an,” and “the” include plural referents unless the context clearly dictates otherwise.
It should be emphasized that the term “comprises/comprising” when used in this specification is taken to specify the presence of stated features, integers, steps, or components but does not preclude the presence or addition of one or more other features, integers, steps, components, or groups thereof.
The present invention addresses challenges in risk adjustment coding by providing a neurosymbolic auditing framework for automated Hierarchical Condition Category (HCC) coding healthcare systems. Risk adjustment systems may be used to ensure that insurance providers receive appropriate compensation based on the expected costs of their members, with health plans covering sicker, higher-cost patients receiving higher payments than plans covering healthier populations. The system may rely on accurately translating a patient’s medical history into ICD10 codes, which then map to Hierarchical Condition Categories (HCC).
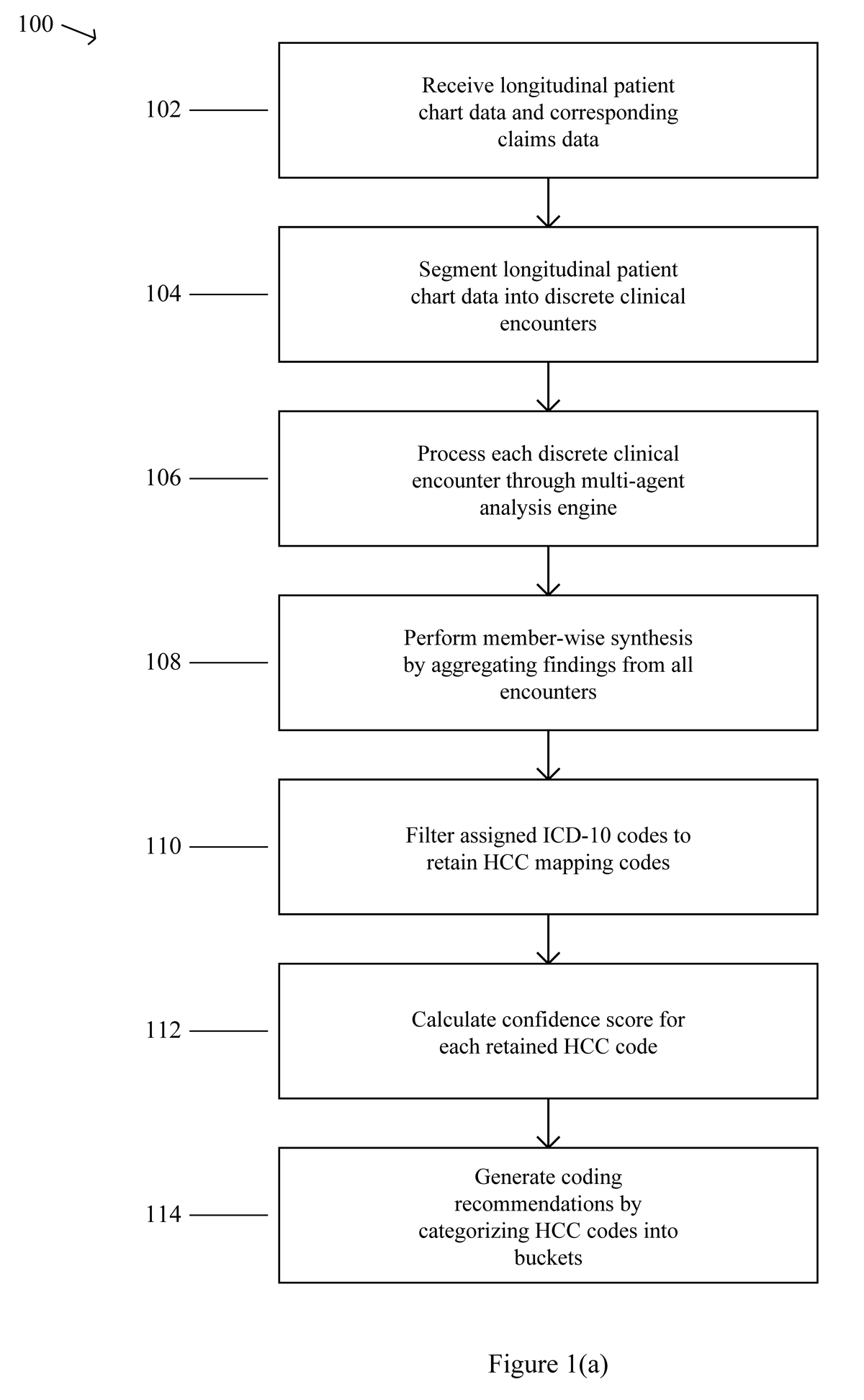
FIG. 1(a) along with FIG 1(b) illustrates a flowchart for a neurosymbolic auditing framework method 100 for automated risk adjustment coding. The method 100 begins with step 102, where the system receives longitudinal patient chart data and corresponding claims data. The process then proceeds to step 104, which involves segmenting the longitudinal patient chart data into discrete clinical encounters based on date of service.
The method 100 continues to step 106, where each discrete clinical encounter is processed through a multi-agent analysis engine comprising a plurality of specialized AI agents that sequentially analyze the clinical encounter to extract clinical data and assign ICD-10 codes. Following this analysis, the process moves to step 108, which performs member-wise synthesis by aggregating findings from all encounters to generate a holistic patient view.
The method 100 then advances to step 110, where assigned ICD-10 codes are filtered to retain only codes that map to Hierarchical Condition Categories (HCC). Subsequently, the process proceeds to step 112, which calculates a confidence score for each retained HCC based on multiple weighted parameters including frequency of documentation across encounters, condition evidence context, and MEAT evidence strength.
The method 100 concludes with step 114, where coding recommendations are generated by categorizing each HCC into either an auto-accept bucket for codes with high confidence scores or a human validation queue for codes with low or medium confidence scores. The flowchart demonstrates a sequential process flow where each step builds upon the previous step’s output, transforming raw longitudinal patient data into structured coding recommendations through automated analysis and intelligent categorization.
The present invention also relates to a method for implementing automated risk adjustment coding in a data processing system. The method comprises the following steps: The neurosymbolic auditing framework may receive longitudinal patient chart data and corresponding claims data for a patient over a given period. The system may process annual patient charts that are typically delivered as single large PDF documents alongside corresponding claims data. The framework may handle data from multiple distinct anonymized datasets representing a wide variety of chart formats, clinical complexities, and data quality levels to ensure robust and generalizable performance across different clinical environments.
The neurosymbolic auditing framework may segment the longitudinal patient chart data into discrete clinical encounters based on DOS. This segmentation process may involve parsing the entire patient chart to identify the DOS for each distinct encounter and establish precise document boundaries for each visit. The segmentation may effectively deconstruct a single, yearlong PDF into multiple, visit-specific documents while extracting and validating demographic details from each visit to detect anomalies and ensure the integrity of the patient record.
The neurosymbolic auditing framework may process each discrete clinical encounter through a multi-agent analysis engine comprising a plurality of specialized AI agents that sequentially analyze the clinical encounter to extract clinical data and assign ICD-10 codes. Each visit-specific document may be processed through the core analysis engine where specialized agents work in sequence to transform raw, unstructured patient data into structured, auditable coding recommendations.
The neurosymbolic auditing framework may perform member-wise synthesis by aggregating findings from all discrete clinical encounters for the patient to generate a holistic patient view. This synthesis process may consolidate all findings from individual visits into comprehensive member-wise perspective, allowing the system to understand the complete patient journey and identify chronic conditions that may be documented across multiple encounters over time.
The neurosymbolic auditing framework may filter the assigned ICD-10 codes to retain only codes that map to Hierarchical Condition Categories (HCC). The filtering process may focus on codes that map to V28 HCC model or RxHCC categories, with the V28 HCC model covering 8,183 ICD-to-HCC mappings with 7,903 unique ICDs and the RxHCC model covering 5,299 mappings with 5,159 unique ICDs to ensure comprehensive coverage of relevant diagnostic categories.
The neurosymbolic auditing framework may calculate a confidence score for each retained HCC based on multiple weighted parameters including frequency of documentation across encounters, condition evidence context, and MEAT evidence strength. The confidence scoring may integrate additional parameters such as code specificity based on similarity between documented evidence and official ICD-10 code descriptions, and condition type weighting that assigns higher weights to chronic conditions compared to acute conditions.
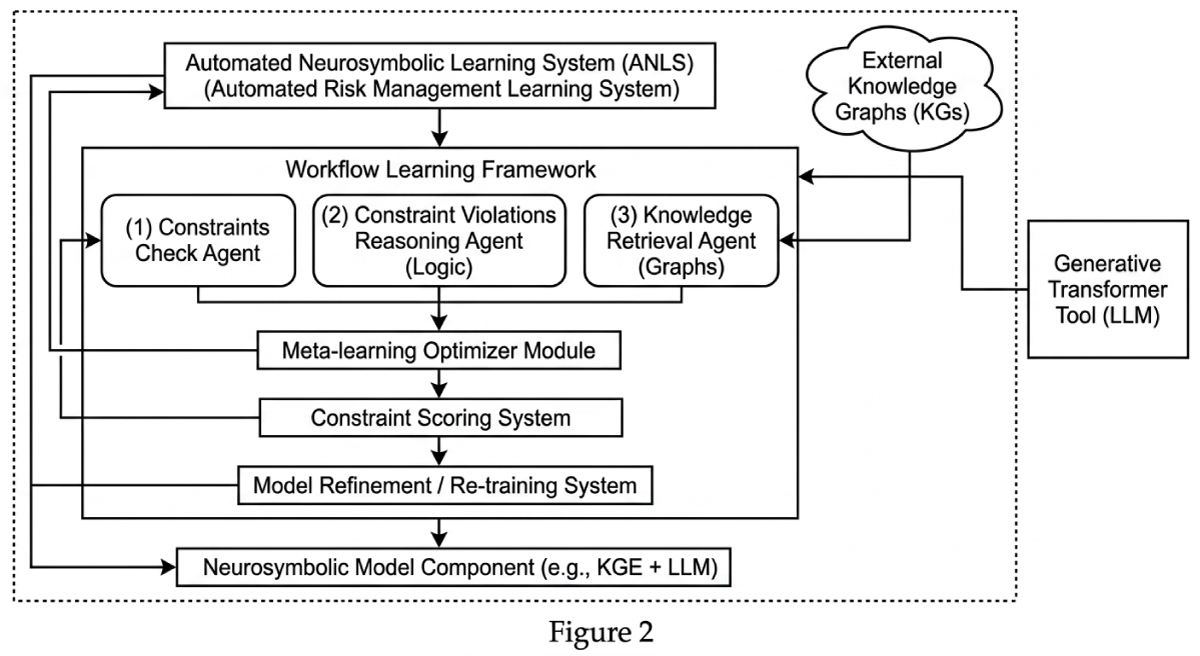
FIG. 2 illustrates a block diagram of an automated risk adjustment coding system 202. The automated risk adjustment coding system 202 includes a data processing system 204, a neurosymbolic auditing framework 210, a medical knowledge graph 230, a demographic validation component 232, and hierarchical suppression logic 234. The data processing system 204 comprises a processor 206 and memory 208. The processor 206 executes instructions stored in the memory 208 to control the operation of the system components. The data processing system 204 is connected to the neurosymbolic auditing framework 210, which serves as the primary processing component for automated HCC coding operations. The neurosymbolic auditing framework 210 contains a multi-agent analysis engine 212, a member-wise synthesis module 224, a confidence scoring system 226, and an output categorization system 228. The multi-agent analysis engine 212 includes five specialized AI agents that operate sequentially: a compliance check agent 214, a clinical data extraction agent 216, a neurosymbolic coding agent 218, a MEAT validation agent 220, and a hallucination validator agent 222.
The multi-agent analysis engine 212 connects to the member-wise synthesis module 224, which aggregates findings from all discrete clinical encounters to generate a holistic patient view. The member-wise synthesis module 224 connects to the confidence scoring system 226, which calculates confidence scores for each retained HCC code based on multiple weighted parameters. The confidence scoring system 226 connects to the output categorization system 228, which implements a triage system to categorize codes into auto-accept buckets or human validation queues. The hallucination validator agent 222 connects to the medical knowledge graph 230, which provides cross-referencing capabilities for validating AI-generated recommendations against established medical knowledge. The neurosymbolic auditing framework 210 connects to the demographic validation component 232, which cross-verifies patient information across encounters to detect anomalies. The output categorization system 228 connects to the hierarchical suppression logic 234, which automatically suppresses redundant codes and filters lower-hierarchy HCC codes to maximize processing efficiency.
The system for automated risk adjustment coding may comprise several interconnected components that work together to implement the neurosymbolic auditing framework. The system architecture may be designed to process longitudinal patient data through a series of specialized components that transform raw clinical information into structured coding recommendations.
(a) A data processing system may include at least one processor and at least one memory comprising instructions that, when executed by the at least one processor, cause the at least one processor to implement the neurosymbolic auditing framework. The data processing system may serve as the foundational computing infrastructure that coordinates all system operations and may be communicatively connected to data sources providing longitudinal patient chart data and corresponding claims data. The processor may execute the instructions stored in the memory to control the operation of all other system components and may manage data flow between the various specialized agents and processing modules.
(b) A neurosymbolic auditing framework may be implemented by the data processing system and may be configured to receive longitudinal patient chart data and corresponding claims data for a patient over a given period. The neurosymbolic auditing framework may be communicatively connected to the data processing system and may coordinate the overall workflow from data ingestion through final code recommendations. The framework may combine pattern-recognition capabilities of neural networks with structured reasoning of large knowledge models to perform comprehensive analysis of patient records.
(c) A multi-agent analysis engine may be integrated within the neurosymbolic auditing framework and may comprise a plurality of specialized AI agents that sequentially analyze clinical encounters. The multi-agent analysis engine may be communicatively connected to the neurosymbolic auditing framework and may receive segmented clinical encounter data for processing. The engine may coordinate the sequential operation of specialized agents including a compliance check agent, a clinical data extraction agent, a neurosymbolic coding agent, a MEAT validation agent, and a hallucination validator agent, with each agent passing processed data to the subsequent agent in the pipeline.
(d) A demographic validation component may be integrated within the segmentation process and may cross-verify patient information across all encounters to detect anomalies such as multiple patients within a single chart. The demographic validation component may be communicatively connected to the encounter segmentation functionality and may extract demographic details from each visit to ensure data integrity. The component may flag inconsistencies in patient identification information and may prevent processing of corrupted or mixed patient records.
(e) A medical knowledge graph may be integrated within the system and may provide cross-referencing capabilities for recommended codes and their supporting evidence. The medical knowledge graph may be communicatively connected to the hallucination validator agent and may contain structured medical knowledge used to verify the plausibility of coding recommendations. The knowledge graph may store relationships between medical conditions, treatments, and diagnostic codes to enable validation of AI-generated recommendations against established medical knowledge.
(f) An output categorization system may be communicatively connected to the neurosymbolic auditing framework and may implement a triage system that categorizes final output into auto-accept buckets and human validation queues. The output categorization system may receive confidence scores and data source classifications from the framework and may apply decision logic to route codes appropriately. The system may automatically categorize codes with high confidence scores into auto-accept buckets while directing codes with low or medium confidence scores, or those originating from orphan charts or orphan claims, to human validation queues regardless of confidence score.
The neurosymbolic auditing framework may be configured to segment the longitudinal patient chart data into discrete clinical encounters based on DOS, with the segmentation process involving parsing of complete patient charts to identify distinct encounters and establish document boundaries. The framework may process each discrete clinical encounter through the multi-agent analysis engine to extract clinical data and assign ICD-10 codes through sequential agent operations. The framework may perform member-wise synthesis by aggregating findings from all discrete clinical encounters to generate a holistic patient view that captures chronic conditions documented across multiple visits. The framework may filter assigned ICD-10 codes to retain only codes that map to Hierarchical Condition Categories and may calculate confidence scores for each retained HCC based on multiple weighted parameters. The framework may generate coding recommendations by categorizing each HCC based on the calculated confidence score through the output categorization system. The system may further comprise integration interfaces configured to communicate with existing healthcare information systems to receive patient data and transmit coding recommendations.
The advantages of the present invention may include substantial improvements in coding accuracy and efficiency compared to traditional manual processes. The member-wise approach may enable identification of chronic conditions that span multiple encounters, reducing missed diagnoses that occur in fragmented DOS-wise reviews. The automated confidence scoring and triage system may reduce manual workload by enabling straight-through processing of highconfidence codes while focusing human expertise on complex cases requiring nuanced judgment. The system may achieve high precision in auto-accepted codes while maintaining comprehensive coverage with minimal manual additions, thereby reducing coder fatigue and improving overall accuracy in risk adjustment operations.
The advantages of the present invention may include substantial improvements in coding accuracy and efficiency compared to traditional manual processes. The member-wise approach may enable identification of chronic conditions that span multiple encounters, reducing missed diagnoses that occur in fragmented DOS-wise reviews. The automated confidence scoring and triage framework may reduce manual workload by enabling straight-through processing of high-confidence codes while focusing human expertise on complex cases requiring nuanced judgment. The framework may achieve high precision in auto-accepted codes while maintaining comprehensive coverage with minimal manual additions, thereby reducing coder fatigue and improving overall accuracy in risk adjustment operations.
Further, the experiment is conducted on four distinct, anonymized datasets sourced from real-world clinical operations. These data sets represent a wide variety of chart formats, clinical complexities, and data quality levels, thereby ensuring a robust and generalizable evaluation of the system’s performance. For each member in the datasets, the available information included one full year of clinical charts and the corresponding claims data. A set of correct and auditable HCC codes was established for each member. A number of implementations have been described. Nevertheless, it will be understood that various modifications may be made without departing from the spirit and scope of the disclosure. Accordingly, other implementations are within the scope of the following claims.
Experimental Methodology
The evaluation for each member in the datasets may follow a systematic data processing workflow that applies the agents in a sequential manner. The evaluation process may comprise four distinct phases: (1) Ingestion and Segmentation, where for each member, the complete one-year clinical chart and claims data may be ingested, and the encounter segmentation agent may parse the longitudinal chart to identify and isolate each discrete clinical encounter into a separate, visit-specific document; (2) Encounter-Level Analysis, where each segmented encounter may be subsequently processed by the multi-agent core analysis engine through sequential application of the compliance check agent, the clinical data extraction agent, the neurosymbolic coding agent, the MEAT validation agent, and the hallucination validator agent to produce a set of validated findings for each visit; (3) Member-Wise Synthesis and Scoring, where following the analysis of all encounters for a member, the framework may perform member-wise synthesis by aggregating all findings and retaining only ICD-10 codes mapping to V28 HCC or RxHCC categories, with the system calculating a final confidence score for each unique code based on the consolidated evidence; and (4) Triage for Evaluation, where the system may apply the decision framework to triage the scored recommendations by categorizing each code into either the auto-accept bucket or the human validation queue, with this final categorized output forming the basis for performance evaluation.
The final output from the experimental workflow may be categorized for analysis into several distinct groups, allowing for a granular assessment of the system’s performance. The framework may categorize as-
Total System Recommendations as the complete set of unique ICD-10 codes suggested by the framework for a member, prior to any human interaction.
Auto-Accepted Recommendations may comprise a subset of recommendations that the system identified with HIGH confidence.
Recommendations Flagged for Human Review may include codes that the system identified with LOW or MEDIUM confidence, or those originating from orphan charts/claims, with this queue including Unclaimed Codes representing potential under-coding and Overclaimed Codes representing potential over-coding.
Manual Code Additions may comprise any valid codes that were missed entirely by the system and subsequently added by the human coder during their final review.
Results
To provide a rigorous quantitative evaluation, the framework may define five key metrics. Let M be the set of all members in the evaluation dataset. For a given member m E M, the following sets of codes may be defined:
- SAA(m) as the set of codes placed in the Auto-Accept bucket by the system;
- Sum) as the set of Unclaimed (Net New) codes recommended by the system for human
review; - Som) as the set of Overclaimed codes flagged by the system for human review;
- Ssys(m) as the set of all unique codes recommended by the system (SAA(m) U SU(m));
- SMan(m) as the set of valid codes added manually by a human coder that were missed by the
system; and SFinal(m) as the final set of all validated, correct codes for the member (the “gold
standard”).
A validation function, V(C,m), may also be defined, which returns 1 if code C is in the gold standard set SFinal(m), and 0 otherwise. The overall performance metrics may then be calculated by summing the counts across all members:
1. Auto-Accept Precision (PAA): May measure the accuracy of the codes placed in the autoaccept bucket.
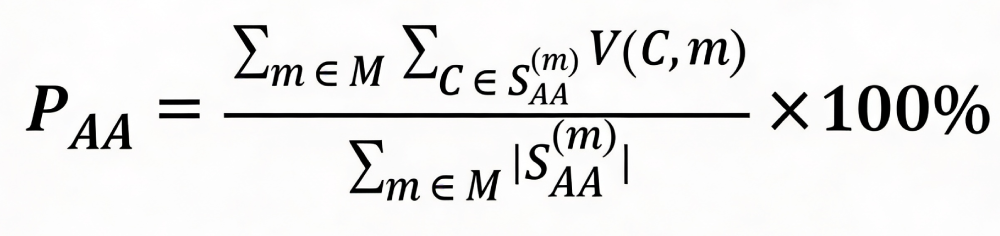
2. Net New Code Discovery Rate (DNN): May measure the system’s effectiveness at identifying valid, under-claimed codes.
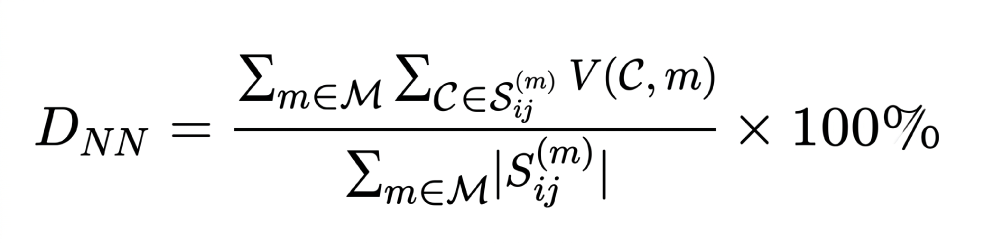
3. Overclaimed Code Rejection Accuracy (AOR): May measure the system’s ability to correctly flag codes from claims that lack sufficient clinical evidence.
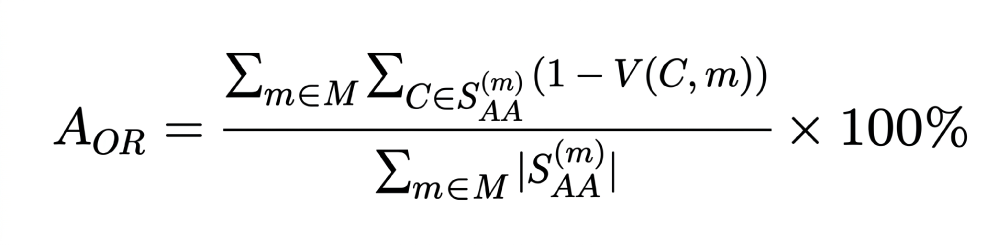
4. Autonomous Coding Rate (RAuto): May represent the proportion of the total recommended codes that were handled automatically.
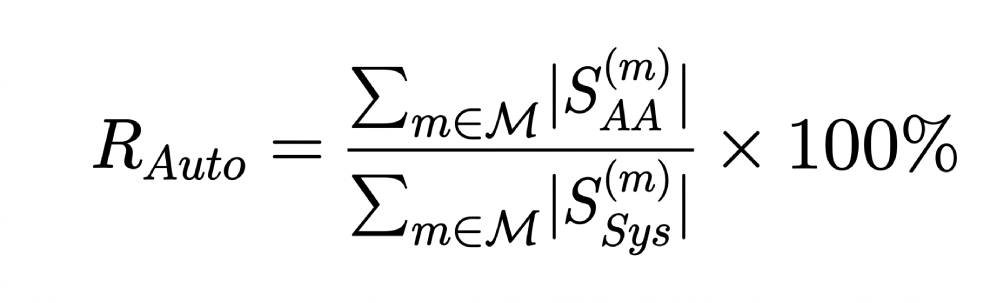
5. Manual Addition Rate (RMan): May measure the dependency on human intervention for codes the system missed entirely.
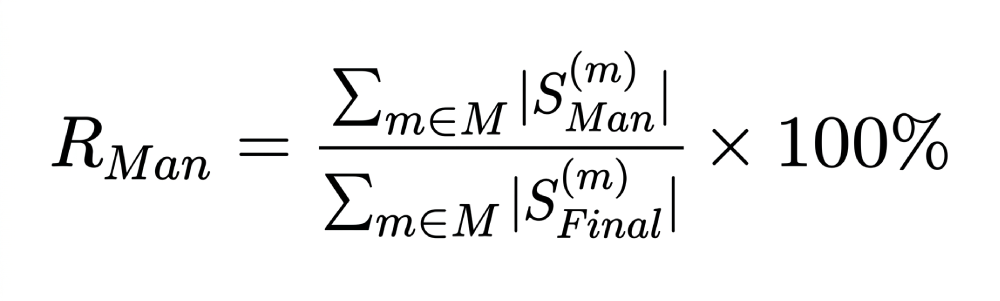
The results presented in Table [XX] may strongly support the initial hypothesis. The high Auto-Accept Precision of 98.29% may demonstrate the robustness of the multi-parameter confidence scoring, confirming that the system may reliably triage a significant portion of codes for straight-through processing. This may directly contribute to the Autonomous Coding Rate of 82.19%, which may signify a substantial reduction in the manualworkload for coding teams. Furthermore, the framework may show strong performance in addressing both under-coding and over-coding. The Net New Code Discovery Rate of [XX.X]% may indicate that the member-wise analysis is highly effective at identifying valid chronic conditions that may be often missed in fragmented, DOS-wise reviews. Conversely, the high Overclaimed Code Rejection Accuracy of [XX.X]% may highlight the system’s ability to enforce compliance by flagging claimed codes that lack the necessary MEAT evidence in the clinical documentation.
Finally, the low Manual Addition Rate of just 1.72% may suggest that the system exhibits high recall, with very few valid codes being missed entirely by the automated analysis. This comprehensive performance may underscore the value of the neurosymbolic, member-wise approach in creating a more accurate, efficient, and compliant risk adjustment process.
Table 1- A detailed breakdown of the system’s output, categorizing all code recommendations across the four datasets and in aggregate. The table presents the raw counts for codes placed in the ‘Auto-Accept’ bucket, those flagged for ‘Required Validation’ (including Unclaimed and Overclaimed), and codes missed by the system and subsequently ‘Added by Coder’. The results highlight the high volume of automated decisions (877 codes in the Auto-Accept bucket overall) and the low number of manual additions (only 17 across all datasets), indicating the framework’s comprehensive coverage and scale.
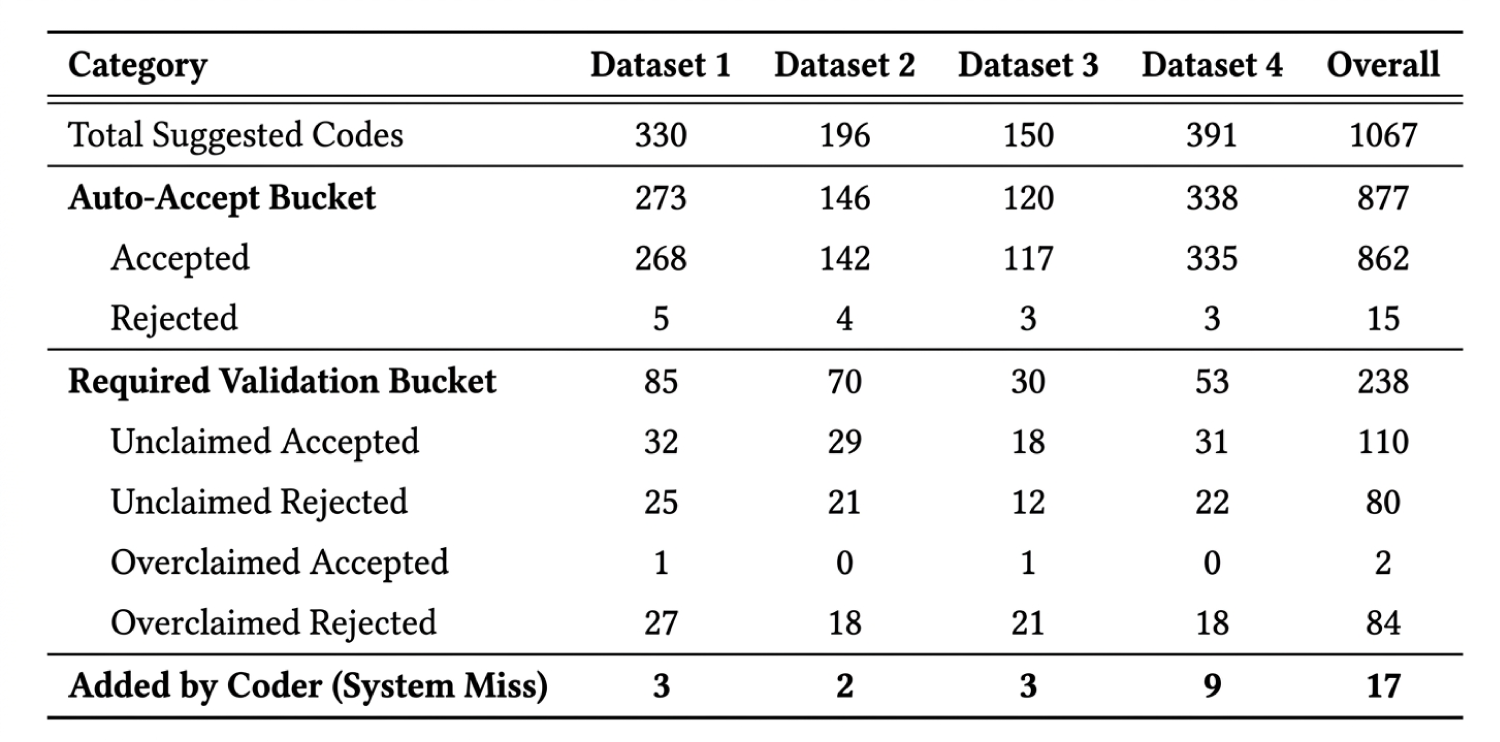
The quantitative results from the experiment, evaluating the neurosymbolic auditing framework against the gold standard across four distinct datasets. The findings may be organized to demonstrate the framework’s performance in terms of recommendation accuracy, its significant impact on coder efficiency through the member-wise paradigm, and a comparative analysis against established human coder reliability benchmarks.
Qualitative Performance Analysis
The framework’s performance may be measured by comparing its output against the gold standard. A detailed breakdown of the raw code counts, including aggregated totals, may be presented in Table 1.
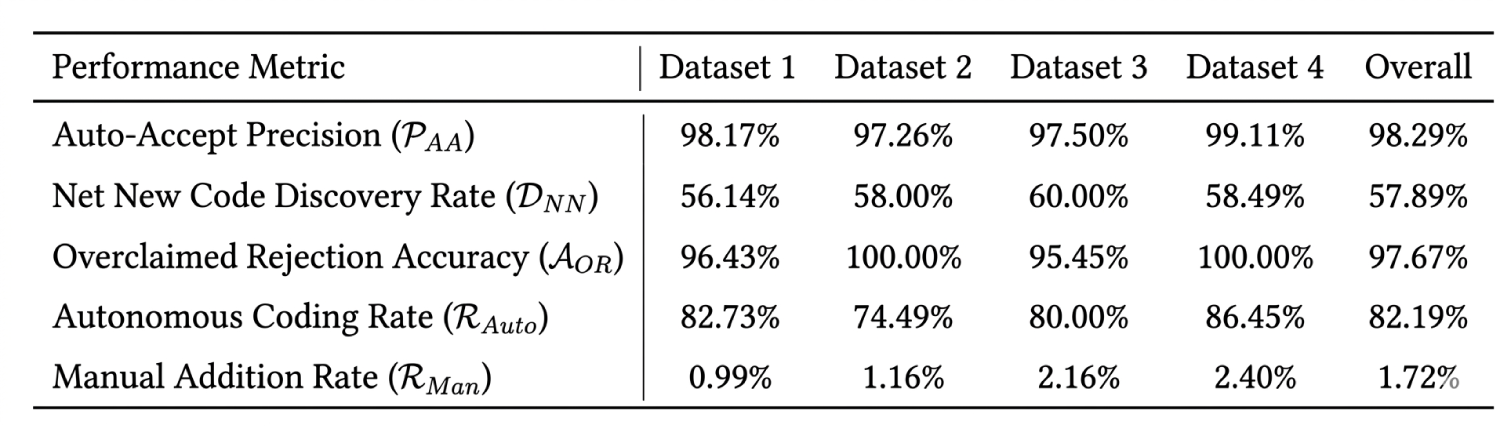
From these counts, the key performance metrics may be calculated, which are summarized in Table 2.
The overall results may highlight the framework’s robustness. An Auto-Accept Precision of 98.29% across 877 high-confidence decisions may validate the reliability of the confidence scoring model. This may enable a high Autonomous Coding Rate of 82.19%, signifying that the majority of the analytical workload can be automated. Furthermore, the extremely low overall Manual Addition Rate of 1.72% may demonstrate the system’s high recall and comprehensive coverage.
Table 2. Summary of the key performance metrics, calculated from the raw data presented in Table 1. This table quantifies the framework’s effectiveness across all four datasets and in aggregate. The results highlight the system’s high reliability, evidenced by an overall Auto-Accept Precision of 98.29%, and its significant impact on workflow, shown by an 82.19% Autonomous Coding Rate. The low Manual Addition Rate of 1.72% further underscores the system’s high recall, confirming that it rarely misses valid codes.
Efficiency Gains: Member-wise va. Dos-wise Curation
A central hypothesis of this work may be that a member-wise audit is not only more accurate but also significantly more efficient. To test this, a comparative case study may be conducted on a representative member, tasking a coder with validating the output of a traditional DOS-wise presentation versus the intelligent member-wise presentation. The results may be summarized in Table 3.
Table 3. A case study comparison illustrating the efficiency gains of the member-wise curation paradigm over a traditional DOS-wise review. For an identical set of 16 system-suggested codes for a single member, this table contrasts the number of items presented to a human coder and the total time required for validation. The member-wise approach, by intelligently suppressing 50% of the codes (8 of 16) that were redundant or hierarchically inferior, reduced the coder’s manual effort and total curation time by 81%. This demonstrates the significant impact of the framework’s synthesis and filtering logic on human productivity.
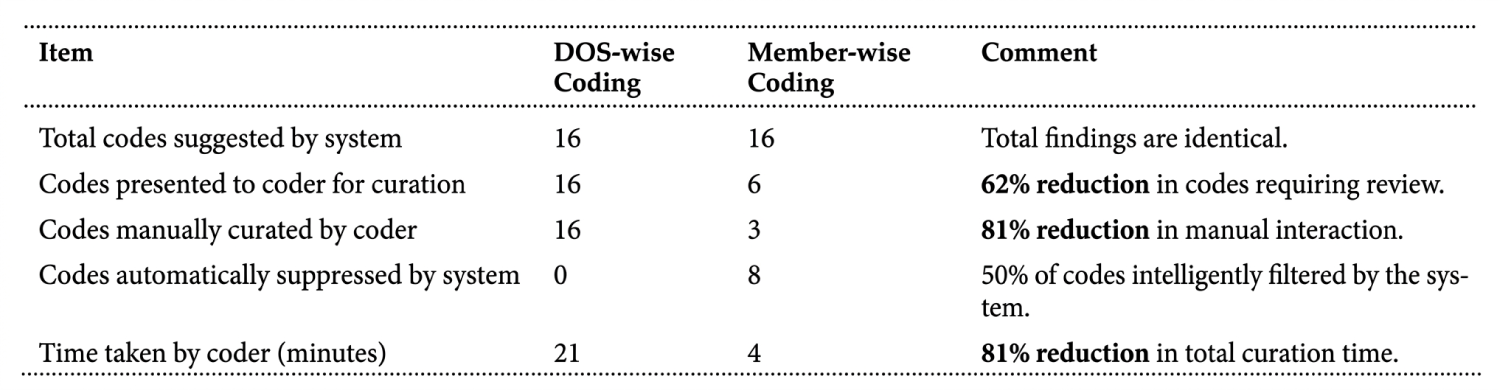
The efficiency gains may be substantial. By aggregating evidence on a member-wise basis, the system’s suppression logic may intelligently filter out redundant, duplicative, or lowerhierarchy HCC. This may reduce the number of codes presented to the coder by 62% and the total time for curation by 81%, confirming that the member-wise paradigm, powered by neurosymbolic AI, may dramatically reduce the cognitive load and manual effort required for validation.
Comparative Analysis Against Human Coder Reliability
To contextualize the system’s performance, the Auto-Accept Precision may be compared to benchmarks of human inter-coder reliability. A study on the consistency of medical coding (PMCID: PMC7299481) may have found that the agreement between human coders for the same condition was approximately 82-86%. The framework’s overall Auto-Accept Precision of 98.29% may significantly exceed this benchmark, suggesting that the system operates not only at the level of a human expert but with a higher degree of consistency than may typically be found between two independent human coders.
Further, the system explicitly handles the common scenarios of misalignment between clinical charts and billing claims.
1. Matched Pair: The ideal scenario where a patient visit chart has a corresponding claim date. These are processed for potential auto-acceptance.
2. Orphan Chart: An encounter for which a clinical chart exists but no corresponding claim has been submitted.
3. Orphan Claim: An encounter for which a claim has been submitted but for which no supporting clinical documentation has been provided.
Further, codes originating from orphan charts or orphan claims are automatically routed for human validation. For matched pairs, the decision is based on the calculated confidence score. Codes with a HIGH score are designated for the Auto-Accept bucket, requiring no further human review. Codes with LOW or MEDIUM scores are flagged for Human Validation. Hierarchical Suppression Logic: To maximize efficiency and prevent redundant coding,a suppression rule is applied.When any code is designated for auto-acceptance, all other codes that map to the same HCC or RxHCC or to a child HCC/RxHCC in the hierarchy, are automatically suppressed for that member. This ensures that only the most confident and highest-value codes are put forward.
We Claim
1. A method (100), in a data processing system to implement a neurosymbolic auditing framework, the method comprising: 2. receiving, by the neurosymbolic auditing framework (210), longitudinal patient chart data and corresponding claims data for a patient over a given period; segmenting, by the neurosymbolic auditing framework (210), the longitudinal patient chart data into discrete clinical encounters based on DOS; processing, by the neurosymbolic auditing framework (210), each discrete clinical encounter through a multi-agent analysis engine (212) comprising a plurality of specialized AI agents that sequentially analyze the clinical encounter to extract clinical data and assign ICD-10 codes; performing, by the neurosymbolic auditing framework (210), member-wise synthesis by aggregating findings from all discrete clinical encounters for the patient to generate a holistic patient view; filtering, by the neurosymbolic auditing framework (210), the assigned ICD-10 codes to retain only codes that map to Hierarchical Condition Categories (HCC); calculating, by the neurosymbolic auditing framework (210), a confidence score for each retained HCC based on multiple weighted parameters including frequency of documentation across encounters, condition evidence context, and MEAT evidence strength; and generating, by the neurosymbolic auditing framework (210), coding recommendations by categorizing each HCC into either an auto-accept bucket for codes with high confidence scores or a human validation queue for codes with low or medium confidence scores.
2. The method of claim 1, wherein the plurality of specialized AI agents comprises: a compliance check agent (214) that verifies each discrete clinical encounter meets regulatory guidelines for HCC coding eligibility; a clinical data extraction agent (216) that extracts medically relevant information based on configurable rules derived from regulatory guidelines; a neurosymbolic coding agent (218) that analyzes extracted clinical data and assigns ICD-10 codes using a large knowledge model; a MEAT validation agent (220) that extracts supporting evidence according to MEAT criteria; and a hallucination validator agent (222) that cross-references recommended codes against a medical knowledge graph (230).
3. The method of claim 2, wherein the compliance check agent (214) filters out noncompliant interactions including telephonic-only calls and retains only face-to-face visits for further processing.
4. The method of claim 1, wherein the multiple weighted parameters for calculating the confidence score further comprise: 5. code specificity based on similarity between documented evidence and official ICD-10 code descriptions; and condition type weighting that assigns higher weights to chronic conditions compared to acute conditions.
5. The method of claim 1, wherein performing member-wise synthesis comprises: mapping the assigned ICD-10 codes to V28 HCC model or RxHCC categories; aggregating all associated data points from across all discrete clinical encounters for each valid ICD-10 code; and applying hierarchical suppression logic that automatically suppresses codes mapping to the same HCC or child HCC when a higher confidence code is designated for autoacceptance.
6. The method of claim 5, wherein the hierarchical suppression logic reduces the number of codes requiring human validation by automatically filtering redundant and lower-hierarchy HCС.
7. The method of claim 1, further comprising handling data discrepancies between the longitudinal patient chart data and the corresponding claims data by categorizing encounters as: matched pairs where longitudinal patient chart data corresponds to claim dates; orphan charts where longitudinal patient chart data exists without corresponding claims; and orphan claims where claims exist without supporting longitudinal patient chart data.
8. The method of claim 7, wherein codes originating from orphan charts or orphan claims are automatically routed to the human validation queue regardless of confidence score.
9. A system for automated risk adjustment coding (202), comprising: a data processing system (204) comprising at least one processor (206) and at least one memory (208) comprising instructions that, when executed by the at least one processor (206), cause the at least one processor (206) to implement: a neurosymbolic auditing framework (210) configured to: receive longitudinal patient chart data and corresponding claims data for a patient over a given period, segment the longitudinal patient chart data into discrete clinical encounters based on date of service, process each discrete clinical encounter through a multi-agent analysis engine (212) comprising a plurality of specialized A agents, perform member-wise synthesis by aggregating findings from all discrete clinical encounters for the patient to generate a holistic patient view, filter assigned ICD-10 codes to retain only codes that map to Hierarchical Condition Categories (HCC), calculate a confidence score for each retained HCC based on multiple weighted parameters, and generate coding recommendations by categorizing each HCC based on the confidence score; a multi-agent analysis engine (212) comprising a compliance check agent (214) that verifies regulatory guidelines compliance, a clinical data extraction agent (216) that extracts medically relevant information, a neurosymbolic coding agent (218) that analyzes data and assigns ICD-10 codes, a MEAT validation agent (220) that extracts supporting evidence per MEAT criteria, and a hallucination validator agent (222) that cross-references codes against medical knowledge; a demographic validation component (232) that cross-verifies patient information across encounters and detects anomalies: a medical knowledge graph (230) that provides cross-referencing capabilities and validates AI-generated recommendations; an output categorization system (228) that implements a triage system to route codes to auto-accept buckets or human validation queues based on confidence scores; an encounter segmentation process that segments longitudinal data into discrete clinical encounters; a member-wise synthesis module (224) that aggregates findings across all encounters; a confidence scoring system (226) that calculates scores based on multiple weighted parameters; and a hierarchical suppression logic (234) that automatically suppresses redundant codes and filters lower-hierarchy HCC codes.
10. The system of claim 9, wherein the plurality of specialized AI agents comprises: a compliance check agent (214) that verifies each discrete clinical encounter meets regulatory guidelines for HCC coding eligibility; a clinical data extraction agent (216) that extracts medically relevant information based on configurable rules derived from regulatory guidelines; a neurosymbolic coding agent (218) that analyzes extracted clinical data and assigns ICD-10 codes using a large knowledge model; a MEAT validation agent (220) that extracts supporting evidence according to MEAT criteria; and a hallucination validator agent (222) that cross-references recommended codes against a medical knowledge graph (230).
11. The system of claim 10, wherein the compliance check agent (214) filters out noncompliant interactions including telephonic-only calls and retains only face-to-face visits for further processing.
12. The system of claim 9, wherein the multiple weighted parameters for calculating the confidence score comprise: frequency of documentation across encounters; condition evidence context based on section headers where conditions are documented; MEAT evidence strength based on type of supporting evidence; code specificity based on similarity between documented evidence and official ICD-10 code descriptions; and condition type weighting that assigns higher weights to chronic conditions compared to acute conditions.
13. The system of claim 9, wherein the neurosymbolic auditing framework (210) is further configured to perform member-wise synthesis by: mapping the assigned ICD-10 codes to V28 HCC model or RxHCC categories; aggregating all associated data points from across all discrete clinical encounters for each valid ICD-10 code; and applying hierarchical suppression logic (234) that automatically suppresses codes mapping to the same HCC or child HCC when a higher confidence code is designated for auto-acceptance.
14. The system of claim 13, wherein the hierarchical suppression logic (234) reduces the number of codes requiring human validation by automatically filtering redundant and lowerhierarchy HCC codes.
15. The system of claim 9, wherein the neurosymbolic auditing framework (210) is further configured to handle data discrepancies between the longitudinal patient chart data and the corresponding claims data by categorizing encounters as matched pairs, orphan charts, and orphan claims, and automatically routing codes originating from orphan charts or orphan claims to a human validation queue regardless of confidence score.
16. The system of claim 9, wherein the multi-agent analysis engine (212) is configured to process each discrete clinical encounter through sequential analysis by the plurality of specialized AI agents to extract clinical data and assign ICD-10 codes.
17. The system of claim 9, further comprising a data discrepancy handling module configured to categorize encounters as matched pairs where clinical chart data corresponds to claim dates, orphan charts where clinical chart data exists without corresponding claims, and orphan claims where claims exist without supporting clinical documentation.
18. The system of claim 9, further comprising integration interfaces configured to communicate with existing healthcare information systems to receive patient data and transmit coding recommendations.
19. The system of claim 9, wherein the system is configured to achieve performance metrics including an Auto-Accept Precision rate, an Autonomous Coding Rate, and a Manual Addition Rate for measuring coding accuracy and automation efficiency.
Abstract
The present disclosure provides a method in a data processing system to implement a neurosymbolic auditing framework. The method comprises receiving longitudinal patient chart data and corresponding claims data for a patient, segmenting the data into discrete clinical encounters based on date of service, and processing each encounter through a multi-agent analysis engine comprising specialized AI agents that sequentially analyze the encounter to extract clinical data and assign ICD-10 codes. The method further comprises performing member-wise synthesis by aggregating findings from all encounters, filtering assigned ICD-10 codes to retain codes mapping to Hierarchical Condition Categories (HCCs), calculating confidence scores for each HCC code based on weighted parameters including documentation frequency, condition evidence context, and MEAT evidence strength, and generating coding recommendations by categorizing each HCC code into either an auto-accept bucket for high confidence scores or human validation queue for low or medium confidence scores. Fig. 1(a)