

GRIT — at-a-glance
- TL;DR: GRIT is a geometry-aware LoRA method that concentrates low-rank adaptation along measured curvature, reducing update footprint while preserving quality via K-FAC rank-space preconditioning, Fisher-guided reprojection, and dynamic rank.
- Core mechanism: GRIT performs periodic reprojection of LoRA factors onto top Fisher eigendirections and uses a cumulative eigen-mass rule (with bounds/hysteresis) to pick the effective rank on the fly.
- Update footprint: In the illustrated depth policy (freeze layers 1–10, adapt 11–32), GRIT reduces mean update density and total updated parameters relative to LoRA and LoRA+KFAC, yielding a tighter adaptation footprint across layers.
- Practical overhead: GRIT keeps heavy operations in r × r and triggers few reprojections (about 1.8–2.4 per 1k steps in the timing setup), giving single-digit % mean step-time overhead with P99 spikes aligned to reprojection events.
- What to log / audit: The appendix formalizes an effective capacity multiplier ΞGRIT in terms of effective rank reff , alignment overlap ρalign, and retained mass πproj—actionable telemetry to verify that “geometry-aware compression” is actually happening.
- Limits (be humble): Performance depends on curvature estimation quality (K-FAC assumptions, early Fisher noise) and on the projection frequency knob Tproj, which trades stability for compute.
1 PEFT’s Blind Spot: Learning Inertia & Catastrophic Forgetting
Adapting billion–parameter LLMs stresses memory and bandwidth; PEFT addresses this by freezing most weights and training only a small parameter subset (e.g., low–rank updates). Among PEFT variants, LoRA [Hu et al., 2021] and QLoRA [Dettmers et al., 2023] have become de facto standards. The emerging trade–off: Recent evidence that “LoRA learns less and forgets less” [Biderman et al., 2024] indicates that, relative to full fine–tuning, LoRA’s low–rank update budget often yields smaller gains on hard targets (e.g., code/math) while preserving more of the base model’s broad abilities (e.g., commonsense and general language competence). In short, PEFT often trades peak task improvement for retention:
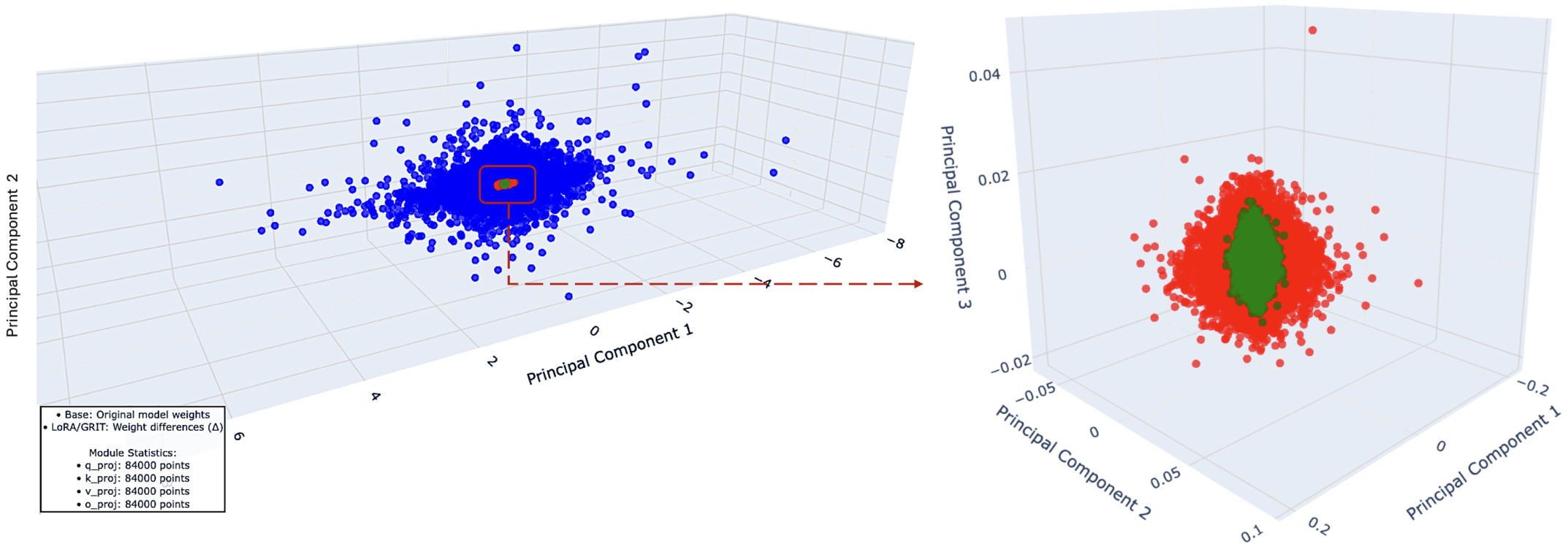
(a) Global view: original model weights vs. LoRA/GRIT ∆-weights in PCA space.
(b) Zoom near the origin comparing LoRA vs. GRIT ∆-weights only
Figure 1: Geometry of parameter updates: GRIT concentrates ∆-weights into curvature-aligned subspaces. Setup. PCA on parameter vectors from attention projections (qproj, kproj, vproj, oproj) across layers; points are meancentered and embedded into the leading PCs (no extra scaling). (a) Overall (left). Blue points depict the entire model’s parameter space as realized by the original (base) weights. Superimposed at the center, red points are LoRA update deltas (∆W), and green points are GRIT update deltas. The visual shows that the full base space is broad and anisotropic, while both LoRA and GRIT operate in a much smaller central region—the effective fine-tuning manifold.
(b) Zoom on ∆ (right). The base cloud is omitted to compare updates directly: red = LoRA ∆W, green = GRIT ∆W. GRIT forms a tighter, ellipsoidal core with reduced radial spread versus LoRA, consistent with rank-space naturalgradient preconditioning and Fisher-aligned reprojection that bias updates toward high-curvature eigendirections while suppressing diffuse, low-signal axes. Interpretation. GRIT densifies signal in a low-rank, curvature-aware subspace (smaller support, tighter covariance) without enlarging the update footprint—steering limited parameters toward directions that matter for stability and generalization.
constrained adapters may underfit challenging distributions yet induce fewer high–impact shifts that erase pretraining knowledge.
1.1 Diagnosis: Learning Inertia vs. High-Impact Updates
2.4 Dynamic Rank Adaptation
Why adapt rank? Reprojection aligns the subspace, but a fixed rank r can still underfit (too few directions) or overfit (retain redundant, low-energy directions). GRIT therefore lets the effective rank track the spectrum. Energy-based rule. Let λ1 ≥ · · · ≥ λr ≥ 0 be eigenvalues of a rank-space covariance (activationor Fisher-side; cf. Secs. 1.1, K-FAC). Define the smallest k capturing energy fraction τ ∈ (0, 1]:
Here “energy” is cumulative variance/mass in leading eigendirections. Constraints and gating. We bound
where min_rank prevents collapse and r is the max LoRA rank at initialization. To avoid early misestimation, we use a warmup gate: updates to k start only after sufficient samples for stable spectra (e.g., EMA/Fisher burn-in).
How adaptation is realized. Rank adaptation is implemented through the reprojection operators. With U(k) the top-k eigenvectors, projectors PA = UA(k)(UA(k))T, PG = UG(k)(UG(k))T suppress low-energy directions during
No hard masking or tensor resizing is required—the directions remain stored and can re-enter if their eigenvalues grow. Update incorporation. After reprojection and rank selection,
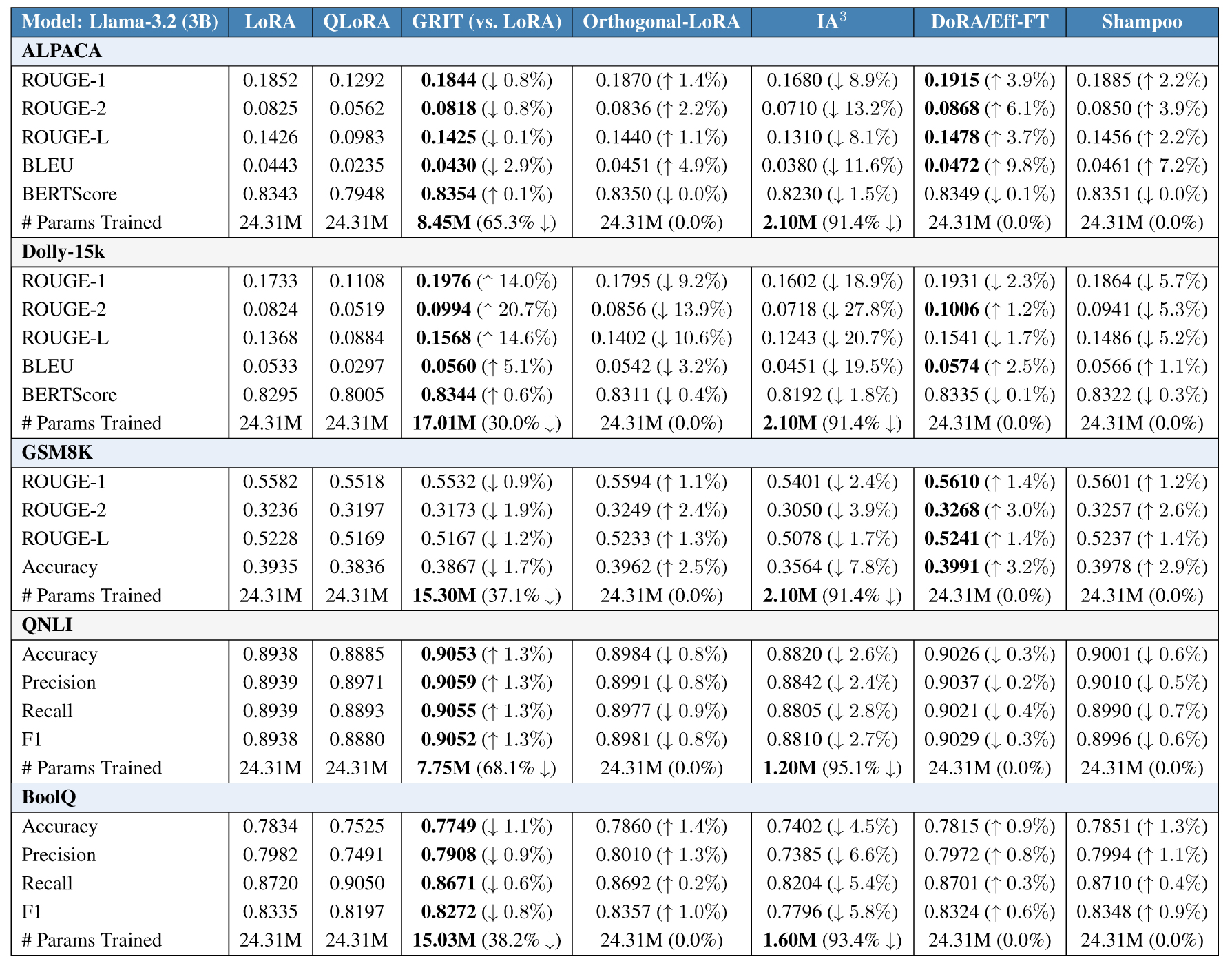
Table 1: Extended baselines on Llama-3.2 3B. Rows are grouped by dataset (blue/gray bands). Each metric cell reports the absolute score followed by a relative delta: for all columns except GRIT, the delta is computed vs. GRIT (↑= higher than GRIT, ↓= lower than GRIT); in the GRIT column, the delta is computed vs. LoRA to show GRIT’s improvement or drop. For ROUGE/ BLEU/ BERTScore/ Accuracy/ Precision /Recall /F1, larger is better; arrows indicate better/worse. Bold marks the best value within the row. The “# Params Trained” rows report the absolute number of trainable parameters for each method and, in parentheses, the % change vs. LoRA (lower is better). This layout makes quality deltas relative to GRIT explicit while exposing GRIT’s parameter savings over LoRA.
For background on natural-gradient/K-FAC curvature handling, see Amari [1998]; Martens and Grosse [2015]; learn–forget trade-offs in PEFT are discussed in Bethune et al. [2022]; Biderman et al. [2024].
How to read the law. At fixed (Df t, N), improving any of {reff, ρalign, πproj} increases ΞGRIT and lowers L GRIT pt . Practically, we recommend reporting Fisher spectra, effective ranks, and alignment proxies alongside task quality so the geometry term is auditable at scale.
5 Conclusion
What we did. We introduced GRIT, a geometryaware PEFT recipe that augments LoRA with three synergistic components: rank-space natural gradients via K-FAC, Fisher-guided reprojection to align updates with dominant curvature, and dynamic rank adaptation to allocate capacity where signal concen trates. Together, these mechanisms steer low-rank updates into high-signal, low-interference directions.
What we achieved. Across instruction-following, classification, and reasoning tasks on LLaMA backbones, GRIT matches or exceeds strong baselines while substantially reducing trainable parameters (typ. ∼46% average, 25–80% ∼tasks), yielding a robust efficiency–quality trade-off. Empirically, GRIT’s curvature-modulated forgetting obeys a power-law with a larger effective capacity factor – consistently lower drift at fixed data and model size.
What’s next. Future work includes stronger curvature estimators beyond rank-space K-FAC, principled schedules for reprojection frequency and rank budgets, and broader evaluations on multimodality.
GRIT – Pipeline
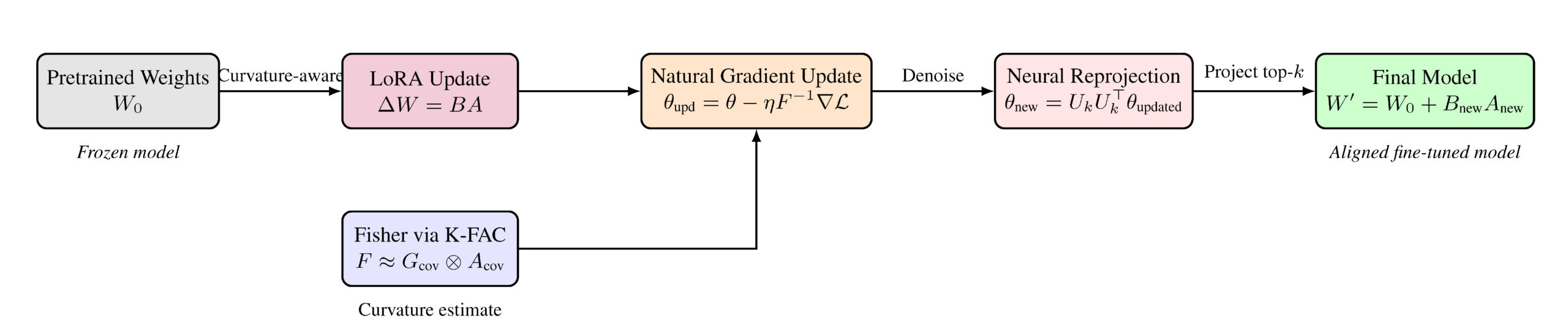
Figure 4: GRIT Geometry-Aware Fine-Tuning Pipeline. Starting from frozen pretrained weights W0, GRIT applies a low-rank update ∆W = BA using LoRA. The Fisher Information Matrix F is approximated using K-FAC to compute a natural gradient update in curvature-sensitive directions. This is followed by a projection onto the dominant eigen-subspace of F via θnew = UkU ⊤ k θupdated, producing the refined update ∆Wnew = BnewAnew. The final model becomes W′ = W0 + ∆Wnew, incorporating only aligned, geometry-aware directions.
Discussion and Limitations
What GRIT contributes. GRIT reframes PEFT as geometry-aware optimization by coupling (i) rank-space K-FAC to approximate natural gradients and temper motion in sharp directions, (ii) neural reprojection that rotates the adapter basis toward Fisher-dominant eigendirections, and (iii) dynamic rank that concentrates capacity where the spectrum has mass. Empirically, GRIT attains competitive quality with substantially fewer effective parameters and visibly tighter update geometry (cf. Figs. 2–1).
Interpretation. Two-sided GRIT allocates capacity to modules whose rank-space Fisher energy—the cumulative mass of eigenvalues {λ (F) i }—persists across intervals. Dominant allocation to o_proj matches attention-output fusion concentrating curvature; lower k on v_proj reflects diffuse value projections. In MLP, up_proj/gate_proj exceed down_proj, consistent with expansion vs. compression. Layer-wise, k rises in mid/late blocks as features specialize.
GRIT on Llama-3.2 3B & Llama-3.1 8B models
Table 2: Consolidated main results on Llama-3.2 3B and Llama-3.1 8B across all tasks. Each block reports absolute scores; bold indicates best-in-block. The “# Param. Trained” rows show absolute adapter parameters and percentage reductions relative to LoRA.
Across tasks, GRIT matches LoRA/QLoRA within 1–3% on median metrics while reducing trainable parameters by 30–68% (model-dependent). Best per-block score in bold.
For background on natural-gradient/K-FAC curvature handling, see Amari [1998]; Martens and Grosse [2015]; learn–forget trade-offs in PEFT are discussed in Bethune et al. [2022]; Biderman et al. [2024].
How to read the law. At fixed (Df t, N), improving any of {reff, ρalign, πproj} increases ΞGRIT and lowers L GRIT pt . Practically, we recommend reporting Fisher spectra, effective ranks, and alignment proxies alongside task quality so the geometry term is auditable at scale.
5 Conclusion
What we did. We introduced GRIT, a geometry a ware PEFT recipe that augments LoRA with three synergistic components: rank-space natural gradients via K-FAC, Fisher-guided reprojection to align updates with dominant curvature, and dynamic rank adaptation to allocate capacity where signal concentrates. Together, these mechanisms steer low-rank updates into high-signal, low-interference directions.
What we achieved. Across instruction-following, classification, and reasoning tasks on LLaMA backbones, GRIT matches or exceeds strong baselines while substantially reducing trainable parameters (typ. ∼46% average, 25–80% ∼tasks), yielding a robust efficiency–quality trade-off. Empirically, GRIT’s curvature-modulated forgetting obeys a power-law with a larger effective capacity factor – consistently lower drift at fixed data and model size.
What’s next. Future work includes stronger curvature estimators beyond rank-space K-FAC, principled schedules for reprojection frequency and rank budgets, and broader evaluations on multimodality.
GRIT – Pipeline
Figure 4: GRIT Geometry-Aware Fine-Tuning Pipeline. Starting from frozen pretrained weights W0, GRIT applies a low-rank update ∆W = BA using LoRA. The Fisher Information Matrix F is approximated using K-FAC to compute a natural gradient update in curvature-sensitive directions. This is followed by a projection onto the dominant eigen-subspace of F via θnew = UkU ⊤ k θupdated, producing the refined update ∆Wnew = BnewAnew. The final model becomes W′ = W0 + ∆Wnew, incorporating only aligned, geometry-aware directions.
Discussion and Limitations
What GRIT contributes. GRIT reframes PEFT as geometry-aware optimization by coupling (i) rank-space K-FAC to approximate natural gradients and temper motion in sharp directions, (ii) neural reprojection that rotates the adapter basis toward Fisher-dominant eigendirections, and (iii) dynamic rank that concentrates capacity where the spectrum has mass. Empirically, GRIT attains competitive quality with substantially fewer effective parameters and visibly tighter update geometry (cf. Figs. 2–1).
Interpretation. Two-sided GRIT allocates capacity to modules whose rank-space Fisher energy—the cumulative mass of eigenvalues {λ (F) i }—persists across intervals. Dominant allocation to o_proj matches attention-output fusion concentrating curvature; lower k on v_proj reflects diffuse value projections. In MLP, up_proj/gate_proj exceed down_proj, consistent with expansion vs. compression. Layer-wise, k rises in mid/late blocks as features specialize.
GRIT on Llama-3.2 3B & Llama-3.1 8B models
Table 2: Consolidated main results on Llama-3.2 3B and Llama-3.1 8B across all tasks. Each block reports absolute scores; bold indicates best-in-block. The “# Param. Trained” rows show absolute adapter parameters and percentage reductions relative to LoRA
Across tasks, GRIT matches LoRA/QLoRA within 1–3% on median metrics while reducing trainable parameters by 30–68% (model-dependent). Best per-block score in bold
Geometry-first fine-tuning. A key takeaway is that where we move in parameter space matters as much as how much. Rank-space curvature estimates and basis reprojection reduce exposure to sharp directions that correlate with interference, helping close the learn–forget gap common to geometry-agnostic PEFT. This lens suggests future PEFT design should co-optimize (loss, curvature, subspace) rather than loss alone.
Concretely, we observe lower curvature exposure κ¯ = tr(P Hpt P) under GRIT versus LoRA at fixed Dft and N, consistent with smaller projections onto sharp modes and reduced drift.
Scope of evidence. Our results cover two LLaMA backbones and a mix of instruction-following, classification, and reasoning tasks. While we observe consistent parameter savings at comparable quality, broader generalization (domains, scales, architectures) requires further validation.
- Curvature estimation bias. Rank-space K-FAC assumes Kronecker separability and relies on finite sample covariances; early-phase Fisher is noisy. We mitigate with damping, EMA smoothing, and warm-up gates, but residual bias may under- or over-allocate rank. Reporting spectra and k(t) traces aids auditability.
- Projection frequency sensitivity. The reprojection period Tproj trades stability and compute. We use hysteresis and sample gates; principled schedules (e.g., trust-region criteria) remain future work.
- Backend coupling. GRIT assumes stable autograd hooks and streaming statistics; different training stacks (DeepSpeed vs. FSDP) can shift the compute/memory envelope. We include configs and seeds for exact replication.
- Task breadth and scale. Evaluations cover two LLaMA backbones and five benchmarks. Generalization to multimodal, multi-turn agents, or RLHF stacks is untested.
- Forgetting quantification. We use pretraining-loss proxies and broad-ability suites; gold-standard drift measures (e.g., pretraining-corpus log-likelihood) are expensive and approximated here.
Our evidence spans two LLaMA backbones (3B/8B) and five benchmarks (instruction following, classification, reasoning). While GRIT consistently reduces trainable parameters at comparable quality, three factors limit external validity: (i) curvature estimation bias from rank-space K-FAC under finite samples; (ii) schedule sensitivity to the reprojection period and τ ; and (iii) stack dependence on FSDP/DeepSpeed configurations. We provide seeds, configs, and logging hooks (Fisher spectra, k(t), πproj) to facilitate independent verification and stress-testing on other domains and architectures.
Spectrum-Driven Rank Allocation
Stability measures. To prevent jitter when eigen-gaps are small, GRIT uses (a) warm-up gating on minimum curvature samples, (b) exponential smoothing of energy curves, and (c) hysteresis around τ . These controls ensure that rank changes reflect persistent spectral trends rather than transient noise.
Limitations and Mitigation Strategies
Broader implications. Coupling curvature and subspace aims to convert parameter efficiency into reliable adaptation. Let Hpt denote the pretraining Hessian (or F a Fisher proxy) and P the projector onto the adapter subspace. Empirically lower curvature exposure κ = tr(P HptP) (or tr(P F P)) aligns with reduced drift [Pascanu et al., 2013; Ghorbani et al., 2019; Keskar et al., 2017]; robust gates, spectral hysteresis, and uncertainty-aware schedules are therefore central to safe deployment.
Reporting protocol for geometry-aware PEFT. To make results auditable at scale, report: (i) per-layer Fisher spectra and cumulative energy E(j); (ii) effective-rank trajectories reff under a fixed τ ; (iii) curvature exposure tr(P HptP) or tr(P F P); (iv) update geometry (tail mass Uhi, norms, sparsity); (v) forgetting proxies (pretraining-loss deltas, zero-shot retention); and (vi) compute overhead of geometry steps. This aligns with scaling-law and continual-learning diagnostics [Bethune et al., 2022; Kirkpatrick et al., 2017; Zenke et al., 2017; Aljundi et al., 2018].
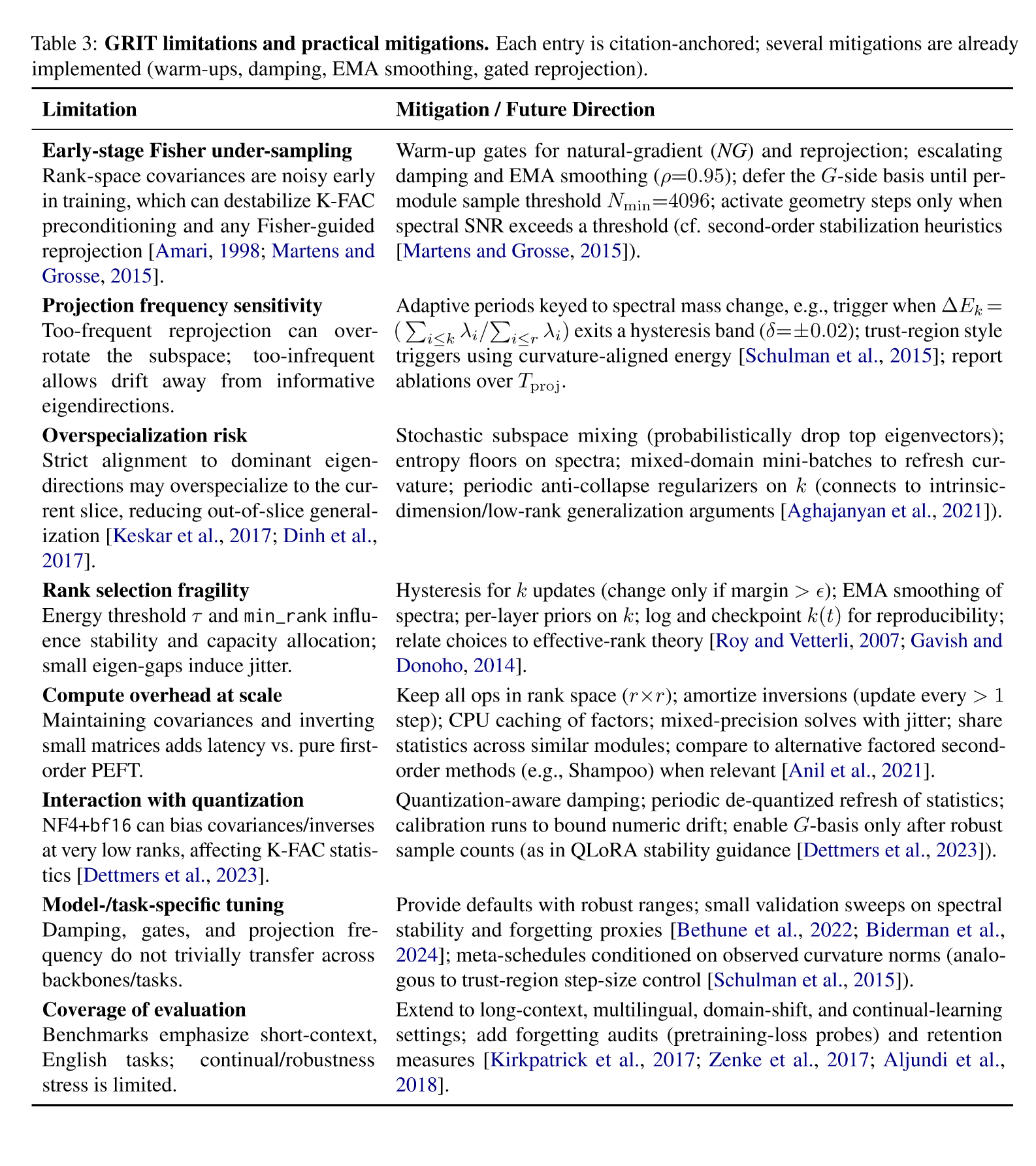
Table 3: GRIT limitations and practical mitigations. Each entry is citation-anchored; several mitigations are already implemented (warm-ups, damping, EMA smoothing, gated reprojection).
Reproducibility Statement
Scope and artifacts. We release all artifacts required to exactly reproduce our results: source code, training/evaluation scripts, configuration files (.yaml), environment files (environment.yml and requirements.txt), experiment manifests (.jsonl), random seeds, and raw evaluation outputs. The repository contains a Makefile with recipes for data preparation, training, checkpointing, and evaluation. We also include a REPORT.md that records command lines, wall-clock times, GPU memory, and commit hashes for every run.
Hardware. All experiments were run on NVIDIA A100 80GB GPUs (SXM4), except Llama 3.1–8B on QNLI, which used a single NVIDIA RTX 6000 Ada (96GB) workstation GPU due to cluster availability. Each run used mixed precision on tensor cores. Host CPUs were dual Intel Xeon Silver 4314 or AMD EPYC 7452; system RAM ≥ 256 GB. Experiments were orchestrated with slurm and torchrun.
Software environment. We provide an exact, pinned software stack and export a conda environment file. Reproducing on different CUDA/cuDNN versions is typically benign but may cause ±0.1–0.3pt jitter in text metrics due to kernel and RNG differences.
Models, datasets, and preprocessing. We evaluate Llama 3.2–3B and Llama 3.1–8B (HF checkpoints). Datasets: Alpaca (52k), Dolly 15k, BoolQ, QNLI (GLUE), GSM8K. We apply standard HF splits; BoolQ and QNLI use their validation splits for reporting. Text normalization: UTF-8, strip control characters, collapse repeated whitespace, and truncate/pad to the configured max sequence length. Prompt formats for instruction datasets follow the Llama instruction template provided in the repo (templates/llama_inst_v1.json). For GSM8K we evaluate both generative (exact-match) and reference-based metrics; we use the official answer normalization script.
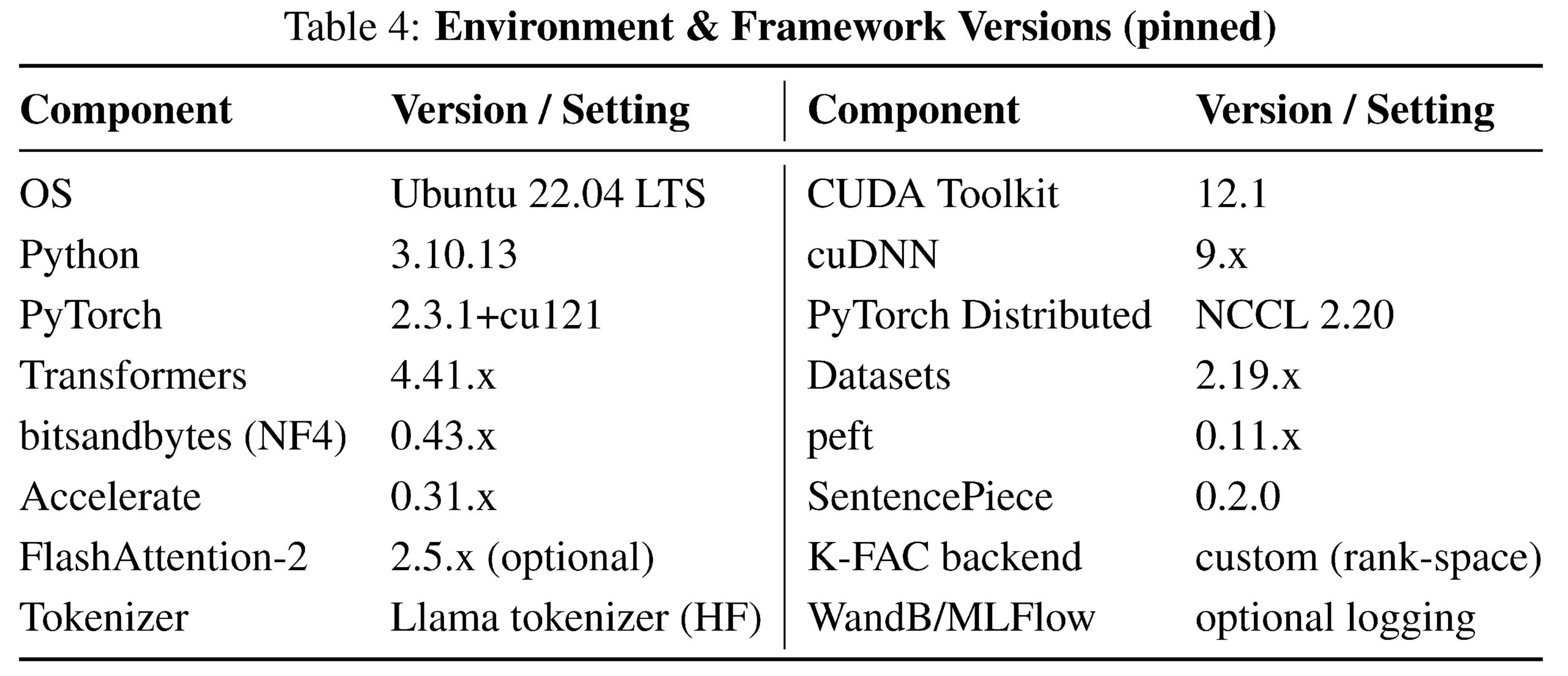
GRIT configuration (default unless stated). We quantize the backbone with 4-bit NF4 weights and bf16 compute (QLoRA setting). Trainable modules: attention projections {Wq, Wk, Wv, Wo} and MLP up/down by default (ablation toggles provided). Initial LoRA rank rmax∈ {8, 16, 32} depending on model size and task; dynamic rank adaptation reduces the effective rank online. K-FAC is applied in rank space. Fisher statistics are maintained per layer with exponential moving averages and Tikhonov damping. Neural reprojection is executed periodically based on curvature-sample gates. Full hyperparameters appear in Table 5; per-task overrides in Table 6.
Training determinism and seeds. We fix RNG seeds for Python, NumPy, and PyTorch; enable torch.backends.cudnn.deterministic=True and benchmark=False; fix dataloader shuffles with generator=torch.Generator().manual_seed(seed) and worker_init_fn. We run 3 seeds {41, 42, 43}
Table 5: GRIT hyperparameters (shared defaults). Symbols match those used in the paper
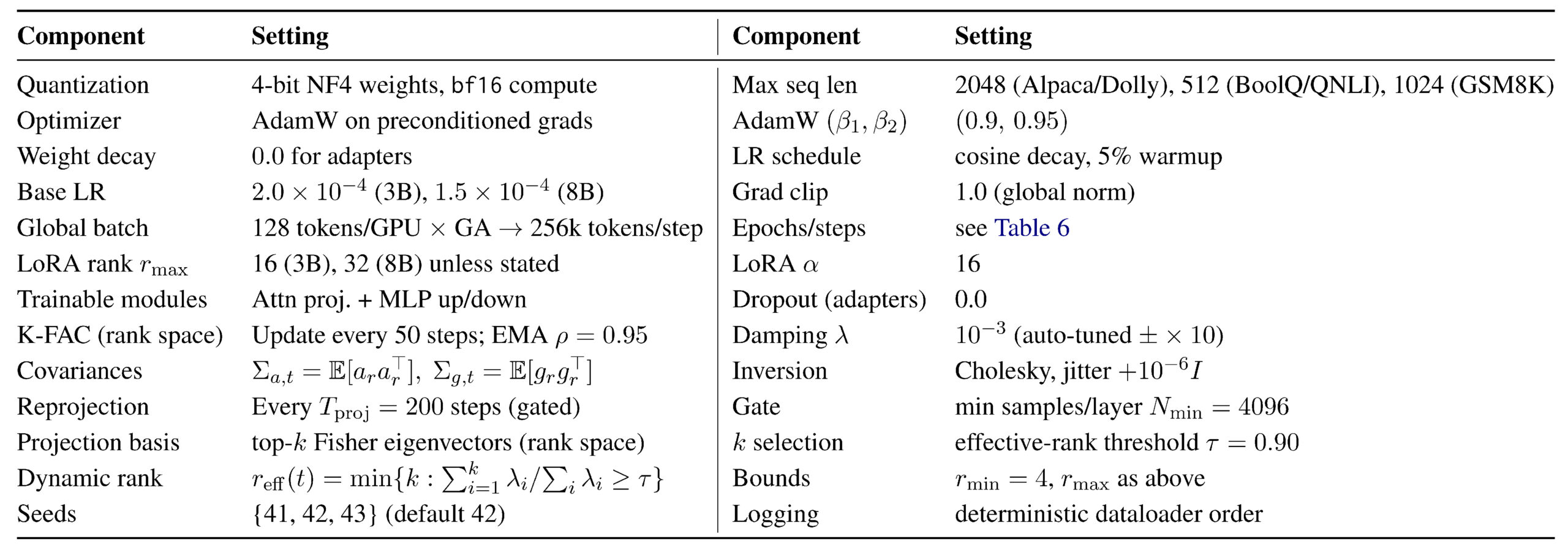
Table 6: Per-task schedules (& overrides). Steps shown for 3B; the 8B model uses the same token budgets with proportionally longer wall-clock.
and report mean ± std where relevant. Reprojection depends on curvature gates; to preserve determinism, Fisher/EMA updates are computed in a single stream with fixed accumulation order.
Evaluation protocol. We report exact-match accuracy (GSM8K), GLUE metrics (QNLI), and referencebased metrics (ROUGE-1/2/L, BLEU, BERTScore) using pinned versions of evaluate. Decoding for generative metrics uses greedy or temperature 0.2/top-p 0.95 as specified in configs; we fix max_new_- tokens=256 unless the dataset requires otherwise. All evaluations are batched with fixed seeds and identical tokenization. For GSM8K, we use the official answer normalization; we also log per-question chains for auditability.
Per-task overrides. Table 7 lists the main overrides relative to the defaults above; all unlisted knobs use the defaults in the main text.
Table 7: Key hyperparameters by task. Unless specified, batch size is 8, gradient accumulation is 4, epochs=3, learning rate 2 × 10−5.
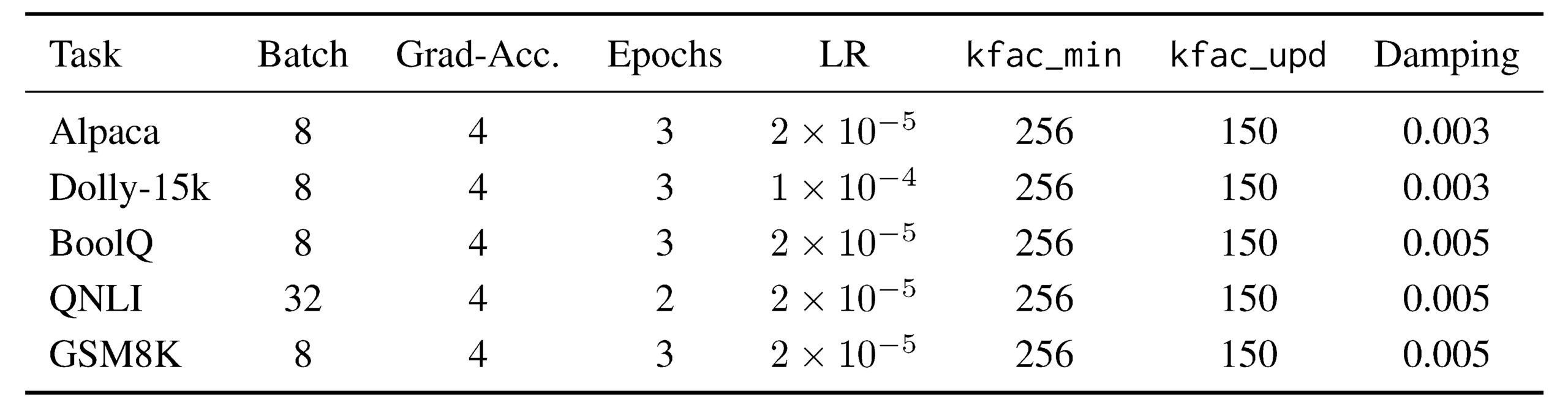
Additional long-run controls: reprojection_warmup_steps=500, rank_adaptation_start_- step=500; optional NG warmup (e.g., 300 steps for Dolly); and curvature/reprojection regularizers with warmup (λ_K=10−5 , λ_R=10−4 ).
Runtime and Overhead
As summarized in Table 8, GRIT incurs a single-digit mean step-time overhead (∼6–10%) relative to
QLoRA while remaining close in peak memory (+0.5–1.0 GB), with occasional P99 spikes aligned to sparse
reprojection events.
Across IF, NLI, and GSM8K, GRIT’s mean step time is competitive with Orthogonal-LoRA and DoRA/EffFT, and substantially lower than Shampoo, while IA3 remains the lightest method by peak memory (Table 8).
FT, and substantially lower than Shampoo, while IA3 remains the lightest method by peak memory (Table 8). Under a fixed 200k-token budget, GRIT’s wall-clock remains within 0.5–1.2 hours of QLoRA on the 8B backbone, reflecting the small amortized cost of r×r covariance updates and infrequent basis reprojections (Table 8).
Notably, the adaptive cadence (∆ eigen-mass + hysteresis) yields only 1.8–2.4 reprojections per 1k steps across tasks, explaining the modest P99 inflation without impacting average throughput (Table 8). Config. A100 80GB; bf16 params + NF4 activations (for QLoRA/GRIT); seq len 2,048; global batch = 128 tokens/step (effective); grad acc = 8; AdamW; eval disabled during timing. Fixed token budget: 200k tokens. Backbone: LLaMA-3-8B. Tasks: Inst-Follow (IF), NLI, GSM8K.
Table 8: Compact runtime/overhead summary across baselines and GRIT. GRIT keeps heavy ops in r×r and uses sparse reprojections, yielding single-digit % mean step-time overhead vs. QLoRA. P99 spikes for GRIT align with reprojection events.
Reading. Overhead: GRIT adds ∼6–10% mean step-time over QLoRA; P99 spikes coincide with reprojection events. Memory: GRIT ∼QLoRA (+0.5–1.0 GB) due to rank-space stats; IA3 is the lightest.
Ablations and controls. The code exposes switches for: disabling K-FAC (first-order baseline in the same subspace), disabling reprojection, fixing rank (no dynamic adaptation), attention-only vs. MLP-only adapters, rank grids {4, 8, 16, 32}, reprojection intervals {100, 200, 400}, and damping grids {10−4 , 10−3 , 10−2}. Each ablation inherits all other settings from the default .yaml to isolate the targeted factor.
Compute budget and runtime. On a single A100 40GB, 3B runs typically require 8–14 GPU hours per task; 8B runs require 18–30 hours. K-FAC rank-space updates add ≈ 6–10% step overhead; reprojection adds a short burst (≤ 0.5 s) every Tproj steps for r×r eigendecompositions (negligible at r≤32). Peak memory: 24–32 GB for 3B, 36–44 GB for 8B with NF4+bf16.
Licensing, data usage, and ethics. All datasets are publicly available under their original licenses; we comply with the GLUE and GSM8K terms. Our code is released under a permissive research license; see LICENSE. We provide DATA_CARDS.md with dataset origins and preprocessing steps.
How to reproduce. After creating the provided conda env, run:
make train TASK=alpaca MODEL=llama-3.2-3b SEED=42 \
CFG=configs/grit_llama3b.yaml OUT=./runs/alpaca_llama3b_s42
make eval TASK=alpaca CKPT=./runs/alpaca_llama3b_s42/best.pt
This invokes the exact configuration used in the paper (commit hash recorded in runs/*/meta.json). The same applies to other tasks/models via TASK={dolly15k,boolq,qnli,gsm8k} and MODEL={llama-3.2-3b,llama3.1-8b}.
Deviations and caveats. The only hardware deviation is the RTX 6000 Ada run for 8B/QNLI. We observed no metric drift beyond expected RNG jitter. If reproducing on alternative drivers/CUDA, minor numeric differences may arise; we recommend re-running all three seeds to match reported means.
Artifact checklist. Repo contents: code; configs (.yaml); env files; scripts for training/eval; seeds; logs; metric JSON; ablation scripts; plotting scripts for spectra/effective ranks; and READMEs with end-to-end instructions. All figures are generated from logged runs via scripts/plot_*.py; we provide notebooks to regenerate Figures 2 to 4.
Ethics Statement
Scope and intent. This work introduces GRIT, a geometry-aware, parameter-efficient fine-tuning (PEFT) method that modifies how adaptation proceeds, not what data are used or which capabilities are unlocked. We position GRIT within standard model-governance practices (e.g., model cards, datasheets, and data statements) to ensure transparency around intended use, training data provenance, and evaluation scope [Mitchell et al., 2019; Gebru et al., 2021; Bender and Friedman, 2018].
Dual use and misuse. Lowering the cost of adaptation can enable beneficial customization and harmful repurposing (e.g., spam, fraud, disinformation). We therefore advocate (i) release strategies conditioned on risk, consistent with staged disclosure and use-policy alignment [Solaiman et al., 2019; Weidinger et al., 2021]; (ii) integrating red teaming and adversarial audits (prompt attacks, jailbreaks) into any GRIT deployment [Perez et al., 2022; Zou et al., 2023]; and (iii) publishing auditable geometry traces (Fisher spectra, effective ranks) to diagnose suspicious training dynamics and drift.
Bias and fairness. GRIT alters update geometry rather than content, and thus can propagate pre-existing biases if data or objectives are skewed. We recommend slice-aware, dataset-grounded evaluation (toxicity, demographic performance, and robustness) with established probes and taxonomies [Gehman et al., 2020; Blodgett et al., 2020; Sheng et al., 2019]. We further encourage coupling GRIT with documentation artifacts (model cards/datasheets) and accountability practices [Mitchell et al., 2019; Gebru et al., 2021; Raji et al., 2020].
Privacy. Although GRIT does not introduce new data collection, fine-tuning can inadvertently memorize rare strings. We recommend data de-duplication and PII scrubbing where feasible, and post-hoc membership/memorization checks [Carlini et al., 2019, 2021; Shokri et al., 2017]. Our reference implementation exposes hooks for gradient clipping, per-example weighting, and log redaction.
Environmental impact. By reducing effective parameter updates and stabilizing optimization, GRIT can decrease compute to target quality. We will report estimated energy/CO2e per run and provide configuration defaults (lower ranks, early stopping via geometry metrics) aligned with established footprint reporting practices [Strubell et al., 2019; Henderson et al., 2020; Lacoste et al., 2019].
Transparency, reproducibility, and auditing. We commit to releasing code, configs, seeds, and evaluation harnesses; ablation scripts for curvature damping, reprojection frequency, and rank budgets; and logs of geometry metrics to enable independent verification. This aligns with evolving reproducibility norms and checklists in ML [Pineau et al., 2021; Liang et al., 2022]. We also recommend licensing under responsible-AI terms (e.g., RAIL) to bind usage to acceptable-intent policies [rai, 2023].
Limitations and open risks. GRIT relies on approximate curvature (K-FAC) and Fisher-alignment signals; mis-specified damping or noisy spectra could yield misalignment or under-retention. Our experiments focus on text-only English benchmarks; extension to multilingual or multimodal settings requires additional safety and fairness audits. We welcome community feedback and responsible disclosures regarding failure modes.
References
2023. Responsible ai licenses (rail) initiative. https://www.licenses.ai. Accessed 2025-09-24.
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. 2021. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL), pages 7319–7328.
Rahaf Aljundi et al. 2018. Memory aware synapses: Learning what (not) to forget. In ECCV.
Shun-ichi Amari. 1998. Natural gradient works efficiently in learning. In NeurIPS.
Rohan Anil, Vineet Gupta, Tomer Koren, Yoram Regan, and Yair Singer. 2021. Scalable second order optimization for deep learning. In International Conference on Machine Learning (ICML). Shampoo optimizer.
Emily M. Bender and Batya Friedman. 2018. Data statements for natural language processing: Toward mitigating system bias and enabling better science. TACL, 6:587–604.
Louis Bethune et al. 2022. Scaling laws for forgetting. ArXiv:2211. — (update with correct entry).
Stella Biderman et al. 2024. Lora learns less and forgets less. ArXiv:2402. — (update with correct entry).
Su Lin Blodgett, Solon Barocas, Hal Daumé III, and Hanna Wallach. 2020.
Language (technology) is power: A critical survey of “bias” in nlp. In ACL.
Nicholas Carlini, Chang Liu, Úlfar Erlingsson,
eremiah Kos, and Dawn Song. 2019.
The secret sharer: Evaluating and testing unintended memorization in neural networks. In USENIX Security.
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song,
Úlfar Erlingsson, Alina Oprea, and Nicolas Papernot. 2021. Extracting training data from large language models. In USENIX Security.
Arslan Chaudhry, Marc’Aurelio Ranzato, Marcus Rohrbach, and Mohamed Elhoseiny. 2019. Efficient lifelong learning with a-gem. In International Conference on Learning Representations (ICLR).
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. 2019. Boolq: Exploring the surprising
difficulty of natural yes/no questions. In Proceedings of NAACL-HLT, pages 2924–2936.
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, et al. 2021. Training verifiers to solve math word problems. In Advances in Neural Information Processing Systems (NeurIPS).
Felix Dangel, Bálint Mucsányi, Tobias Weber, and Runa Eschenhagen. 2025. Kronecker-factored approximate curvature (kfac) from scratch.
Databricks. 2023. Databricks dolly 15k: A dataset of human-written prompts and responses for instruction tuning. Dataset release.
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. Qlora: Efficient finetuning of quantized llms. NeurIPS.
Laurent Dinh, Razvan Pascanu, Samy Bengio, and Yoshua Bengio. 2017. Sharp minima can have arbitrarily poor generalization for deep nets.
Robert M. French. 1999. Catastrophic forgetting in connectionist networks. Trends in Cognitive Sciences, 3(4):128–135.
Matan Gavish and David L. Donoho. 2014. The optimal hard threshold for singular values is 4/√3. IEEE Transactions on Information Theory, 60(8):5040–5053.
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, and et al. 2021. Datasheets for datasets. Communications of the ACM, 64(12):86–92.
Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A. Smith. 2020. Realtoxicityprompts: Evaluating neural toxic degenerationin language models. In EMNLP.
Behrooz Ghorbani, Samy Jelassi Krishnan, et al. 2019. An investigation into neural network hessians and their spectra. In Proceedings of the 36th International Conference on Machine Learning (ICML), pages 2232–2241.
Roger Grosse and James Martens. 2016. A kronecker-factored approximate fisher matrix for convolution layers. In Proceedings of the 33rd International Conference on Machine Learning (ICML), pages 573–582.
Peter Henderson, Joey Hu, Joshua Romoff, Emma Brunskill, Dan Jurafsky, and Joelle Pineau. 2020.
Towards the systematic reporting of the energy and carbon footprint of machine learning. J. Mach. Learn. Res., 21(248):1–43.
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models.
Nitish Shirish Keskar, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy, and Ping Tak Peter Tang. 2017. On large-batch training for deep learning: Generalization gap and sharp minima.
In International Conference on Learning Representations (ICLR). James Kirkpatrick et al. 2017. Overcoming catastrophic forgetting in neural networks. In PNAS.
Alexandre Lacoste, Alexandra Sasha Luccioni, Victor Schmidt, and Thomas Dandres. 2019. Quantifying the carbon emissions of machine learning.
arXiv:1910.09700.
Percy S. Liang, Rishi Bommasani, and et al. 2022. Holistic evaluation of language models. In NeurIPS. Chin-Yew Lin. 2004. ROUGE: A package for automatic evaluation of summaries. In Workshop on Text Summarization Branches Out.
C. Liu et al. 2024. Dora: Weight-decomposed lowrank adaptation.
H. Liu, D. Tam, et al. 2022. Few-shot parameterefficient fine-tuning is better and cheaper than incontext learning. In Advances in Neural Information Processing Systems (NeurIPS). Introduces IA3 gating for PEFT.
James Martens and Roger Grosse. 2015. Optimizing neural networks with kronecker-factored approximate curvature. In ICML.
Michael McCloskey and Neal J. Cohen. 1989. Catastrophic interference in connectionist networks: The sequential learning problem. In Gordon H.
Bower, editor, Psychology of Learning and Motivation, volume 24, pages 109–165. Academic Press.
Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. 2019. Model cards for model reporting. In FAT*.
Yann Ollivier. 2015. Riemannian metrics for neural networks i: Feedforward networks.
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings
of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318.
Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio. 2013. On the difficulty of training recurrent neural networks. In Proceedings of the 30th International Conference on Machine Learning (ICML), pages 1310–1318.
Ethan Perez, Sam Ringer, Thomas Liao, and et al. 2022. Red teaming language models with language models. In NeurIPS.
Joelle Pineau, Philippe Vincent-Lamarre, Jack Foley, and et al. 2021. Improving reproducibility in machine learning research (a report from the neurips 2019 reproducibility program). J. Mach. Learn. Res., 22(164):1–20.
Inioluwa Deborah Raji, Andrew Smart, Rebecca White, and et al. 2020. Closing the ai account ability gap: Defining an end-to-end framework for
internal algorithmic auditing. In FAT*.
Olivier Roy and Martin Vetterli. 2007. The effective rank: A measure of effective dimensionality. European Signal Processing Conference (EUSIPCO).
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. 2015. Trust region policy optimization. In ICML.
Emily Sheng, Kai-Wei Chang, Premkumar Natarajan, and Nanyun Peng. 2019. The woman worked as a babysitter: On biases in language generation.
In EMNLP.
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. 2017. Membership inference attacks against machine learning models. In IEEE
S&P.
Irene Solaiman, Miles Brundage, Jack Clark, and et al. 2019. Release strategies and the social impacts of language models. arXiv:1908.09203.
Emma Strubell, Ananya Ganesh, and Andrew McCallum. 2019. Energy and policy considerations for deep learning in nlp. In ACL.
T.-T. Vu and Others. 2022. Overcoming catastrophic forgetting in large language models (placeholder).
Placeholder entry; verify exact title/venue or replace with a confirmed work.
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2019.
Glue: A multi-task benchmark and analysis platform for natural language understanding. In Proceedings of ICLR.
Yizhong Wang et al. 2023. Self-instruct: Aligning language models with self-generated instructions.
Laura Weidinger, John Mellor, Maribeth Rauh, and et al. 2021. Ethical and social risks of harm from language models. arXiv:2112.04359.
FirstName Wu and Others. 2024. Continual learning for large language models: A survey.
Friedemann Zenke, Ben Poole, and Surya Ganguli. 2017. Continual learning through synaptic intelligence. In ICML. Tianyi Zhang, Shujian Kishikawa, Mingli Wu, Rowan Zellers, Yi Zhang, and An-Nhi Le. 2019.
Bertscore: Evaluating text generation with bert.
In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural
Language Processing (EMNLP-IJCNLP), pages 5555–5560.
Zheng Zhao, Yftah Ziser, and Shay B. Cohen. 2024. Layer by layer: Uncovering where multi-task learning happens in instruction-tuned large language models.
Andy Zou, Zifan Shi, Nicholas Carlini, and et al. 2023. Universal and transferable adversarial attacks on aligned language models. arXiv:2307.15043.